Pandas
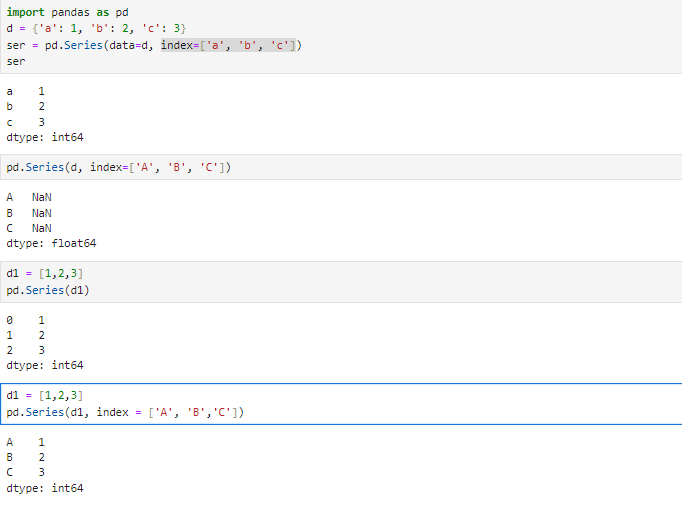
pandas.Series
- class pandas.Series(data=None, index=None, dtype=None, name=None, copy=None, fastpath=False)
import pandas as pd
fruits = ['apples', 'oranges', 'cherries', 'pears']
quantities1 = [20, 33, 52, 10]
quantities2 = [14, 23, 45, 36]
S1 = pd.Series(quantities1, index = fruits)
S2 = pd.Series(quantities2, index = fruits)
S * S1
apples 400 oranges 1089 cherries 2704 pears 100 dtype: int64
import pandas as pd
fruits1 = ['apples', 'oranges', 'cherries', 'pears']
fruits2 = ['raspberries', 'oranges', 'cherries', 'pears']
quantities1 = [20, 33, 52, 10]
quantities2 = [14, 23, 45, 36]
S1 = pd.Series(quantities1, index = fruits1)
S2 = pd.Series(quantities2, index = fruits2)
S1 + S2
apples NaN
cherries 97.0
oranges 56.0
pears 46.0
raspberries NaN
dtype: float64
⇒ 인덱스 다를때 서로 더해주면 같은 인덱스 끼리만 더하고 없는 건 NaN값 반환
import pandas as pd
fruits1 = ['apples', 'oranges', 'cherries', 'pears']
fruits_tr = ['elma', 'portakal', 'kiraz', 'armut']
quantities1 = [20, 33, 52, 10]
quantities2 = [14, 23, 45, 36]
S1 = pd.Series(quantities1, index = fruits1)
S2 = pd.Series(quantities2, index = fruits_tr)
S1 + S2
apples NaN
armut NaN
cherries NaN
elma NaN
kiraz NaN
oranges NaN
pears NaN
portakal NaN
dtype: float64
인덱싱
import pandas as pd
fruits1 = ['apples', 'oranges', 'cherries', 'pears']
fruits_tr = ['elma', 'portakal', 'kiraz', 'armut']
quantities1 = [20, 33, 52, 10]
quantities2 = [14, 23, 45, 36]
S1 = pd.Series(quantities1, index = fruits1)
S2 = pd.Series(quantities2, index = fruits_tr)
S1['oranges']
33
S[['oranges','apples']]
oranges 33
apples 20
dtype: int64
S1['apples':'cherries']
apples 20
oranges 33
cherries 52 dtype: int64
import numpy as np
print((S1+1)*4)
apples 84
oranges 136
cherries 212
pears 44
dtype: int64
print(np.sin(S1))
apples 0.912945
oranges 0.999912
cherries 0.986628
pears -0.544021
dtype: float64
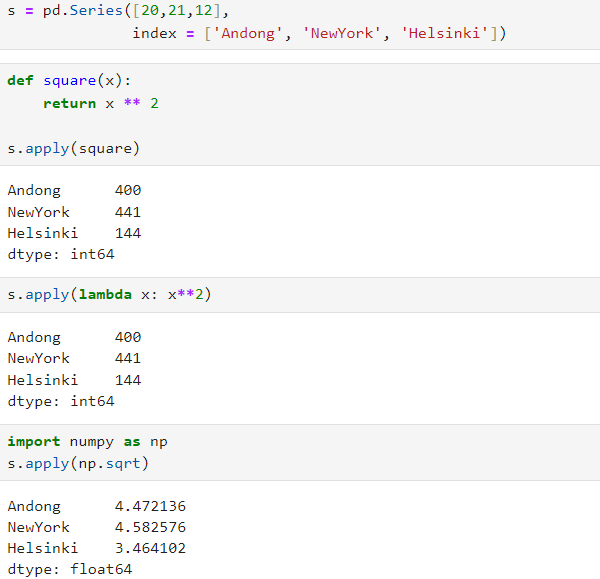
pandas.Series.apply()
- Series.apply(func, convert_dtype=True, args = (), **kwarrgs)
결측값
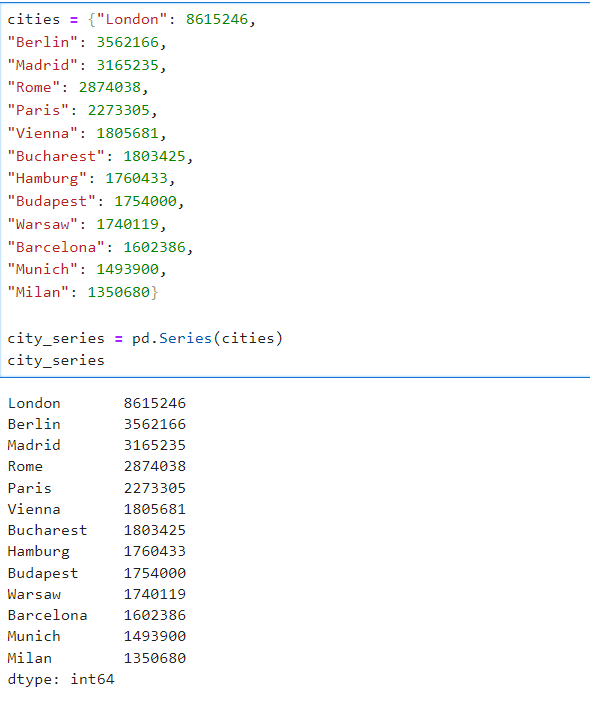
cities = {"London": 8615246,
"Berlin": 3562166,
"Madrid": 3165235,
"Rome": 2874038,
"Paris": 2273305,
"Vienna": 1805681,
"Bucharest": 1803425,
"Hamburg": 1760433,
"Budapest": 1754000,
"Warsaw": 1740119,
"Barcelona": 1602386,
"Munich": 1493900,
"Milan": 1350680}
my_cities = ['London', 'Paris', 'Zurich', 'Berlin','Stuttgart', 'Hamburg']
my_city_series = pd.Series(cities, index = my_cities)
London 8615246.0
Paris 2273305.0
Zurich NaN
Berlin 3562166.0
Stuttgart NaN
Hamburg 1760433.0
dtype: float64
isnull() and notnull()
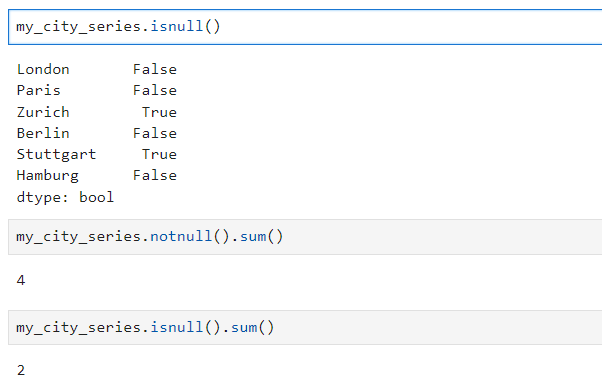
# missing data 제거
my_city_series.dropna()
London 8615246.0
Paris 2273305.0
Berlin 3562166.0
Hamburg 1760433.0
dtype: float64
# missing data 넣어주기
my_city_series.fillna(0)
London 8615246.0
Paris 2273305.0
Zurich 0.0
Berlin 3562166.0
Stuttgart 0.0
Hamburg 1760433.0
dtype: float64
Dataframe
pandas.concat()
- pandas.concat(objs, *, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=None)
# axis = 0 (행 방향)
import pandas as pd
years = range(2014, 2018)
shop1 = pd.Series([2409.14, 2941.01, 3496.83, 3119.55], index=years)
shop2 = pd.Series([1203.45, 3441.62, 3007.83, 3619.53], index=years)
shop3 = pd.Series([3412.12, 3491.16, 3457.19, 1963.10], index=years)
con_shop = pd.concat([shop1, shop2, shop3], axis = 0)
con_shop
2014 2409.14 2015 2941.01 2016 3496.83 2017 3119.55 2014 1203.45 2015 3441.62 2016 3007.83 2017 3619.53 2014 3412.12 2015 3491.16 2016 3457.19 2017 1963.10 dtype: float64
# axis = 1 (열 방향)
import pandas as pd
years = range(2014, 2018)
shop1 = pd.Series([2409.14, 2941.01, 3496.83, 3119.55], index=years)
shop2 = pd.Series([1203.45, 3441.62, 3007.83, 3619.53], index=years)
shop3 = pd.Series([3412.12, 3491.16, 3457.19, 1963.10], index=years)
con_shop = pd.concat([shop1, shop2, shop3], axis = 1)
con_shop
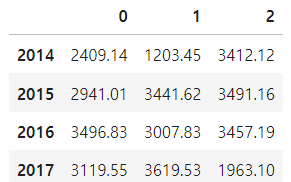
con_shop.columns
RangeIndex(start=0, stop=3, step=1)
con_shop.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 2014 to 2017
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ --------------------- -------
0 0 4 non-null float64
1 1 4 non-null float64
2 2 4 non-null float64
dtypes: float64(3)
memory usage: 228.0 bytes
con_shop.describe()
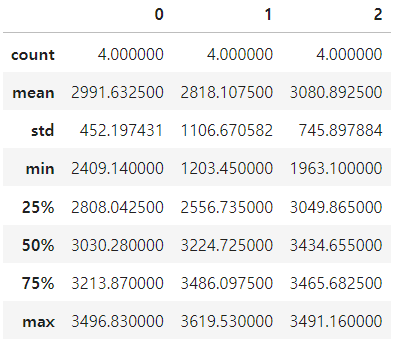
pandas.DataFrame()
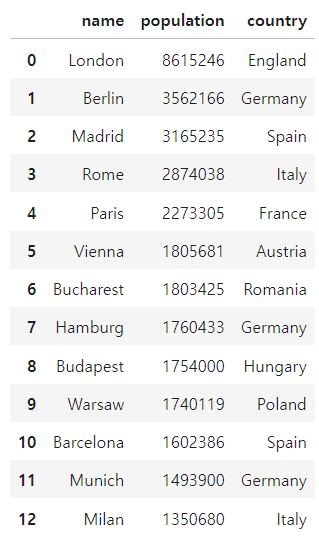
cities = {"name": ["London", "Berlin", "Madrid", "Rome",
"Paris", "Vienna", "Bucharest", "Hamburg",
"Budapest", "Warsaw", "Barcelona",
"Munich", "Milan"],
"population": [8615246, 3562166, 3165235, 2874038,
2273305, 1805681, 1803425, 1760433,
1754000, 1740119, 1602386, 1493900,
1350680],
"country": ["England", "Germany", "Spain", "Italy",
"France", "Austria", "Romania",
"Germany", "Hungary", "Poland", "Spain",
"Germany", "Italy"]}
city_df = pd.DataFrame(cities)
city_df
인덱스 변경
ordinals = ["first", "second", "third", "fourth",
"fifth", "sixth", "seventh", "eigth",
"ninth", "tenth", "eleventh", "twelvth",
"thirteenth"]
city_df = pd.DataFrame(cities, index = ordinals)
city_df
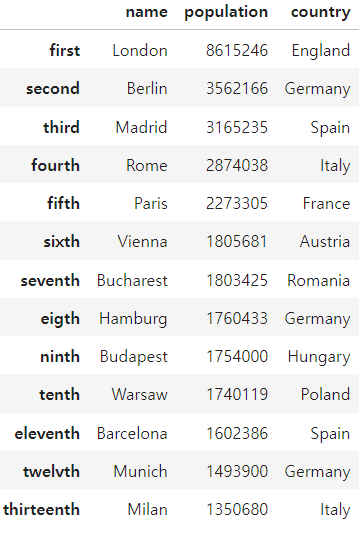
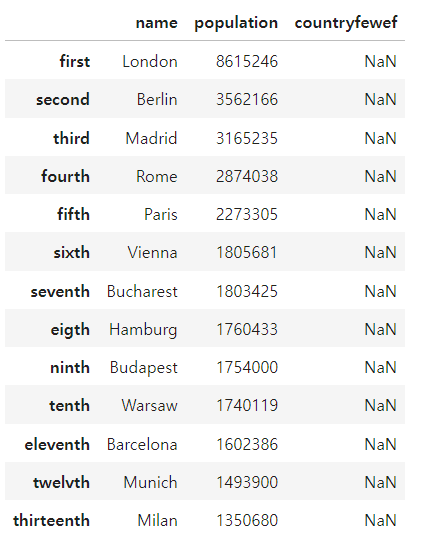
컬럼 변경
columns_name = ['name','population', 'countryfewef']
pd.DataFrame(cities, index = ordinals, columns = columns_name)
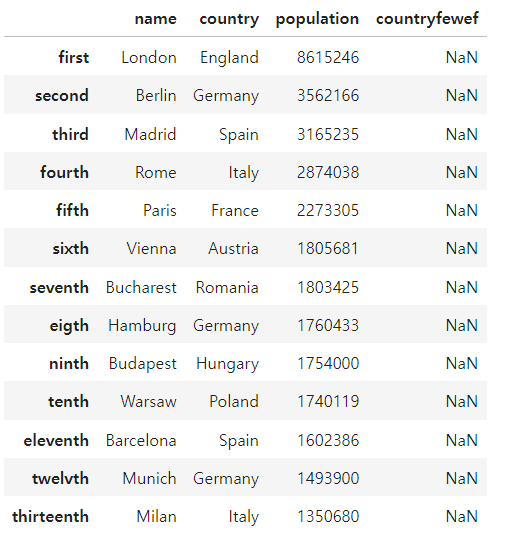
columns_name = ['name','country','population', 'countryfewef']
pd.DataFrame(cities, index = ordinals, columns = columns_name)
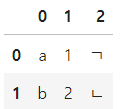
* 꼭 딕셔너리 형태가 아니어도 된다.
data = [('a',1, 'ㄱ'),('b',2,'ㄴ')]
pd.DataFrame(data)
df.head()
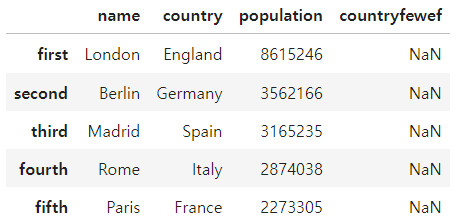
df['name']

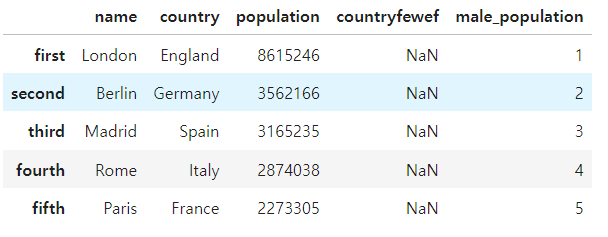
df['male_population'] = [1,2,3,4,5,6,7,8,9,10,11,12,13]
df.head()
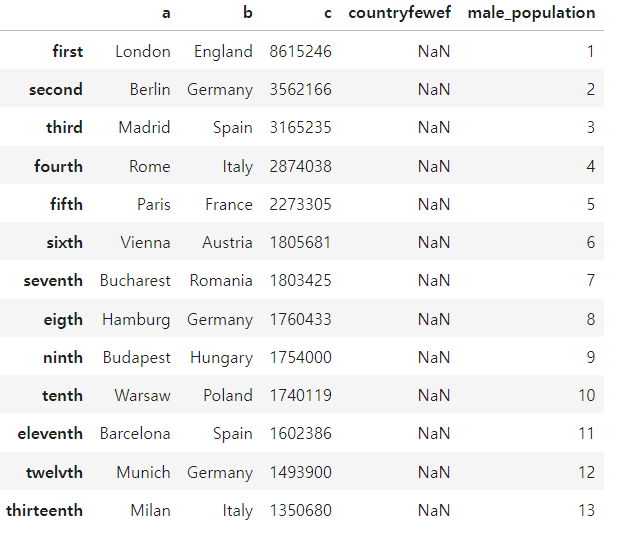
df.rename(columns = {'name':'a',
'country':'b',
'population':'c'
},
inplace = True)
df
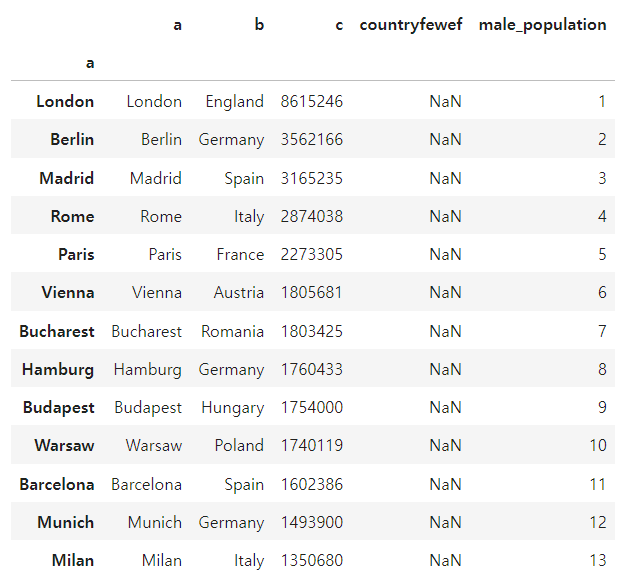
pandas.DataFrame.set_index()
- DataFrame.set_index(keys, *, drop=True, append=False, inplace=False, verify_integrity=False)
df1 = df.set_index('a', drop = False)
df1
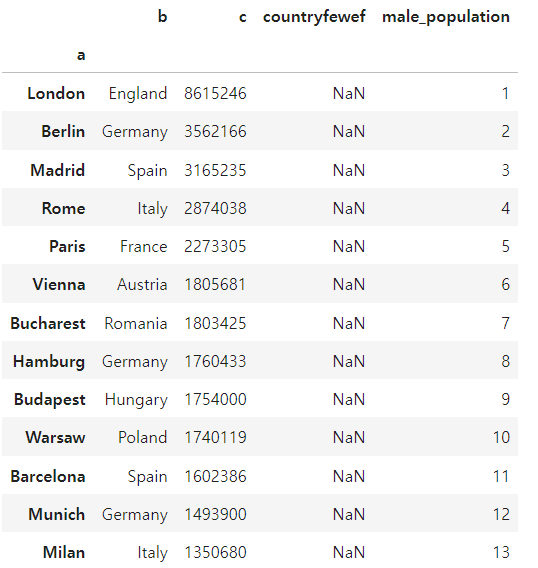
index values() 로 ROWS(행)값 찾기
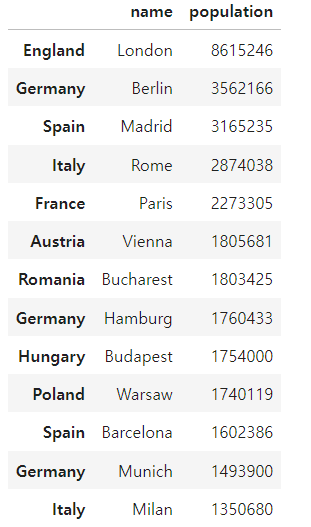
import pandas as pd
city_frame = pd.DataFrame(cities, columns = ['name', 'population'],
index = cities['country'])
city_frame
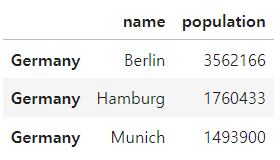
city_frame.loc['Germany']
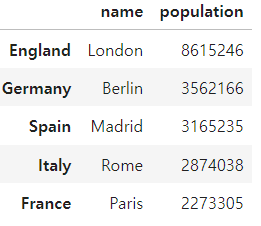
city_frame.loc[city_frame['population']>2000000]
city_frame.loc[(city_frame['population']>2000000) & (city_frame['population']<3000000)]
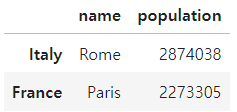
city_frame.loc[(city_frame['population']>2000000) | (city_frame['name'].str.contains('m'))]
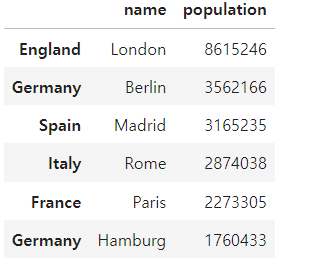
city_frame.loc[(city_frame['population']>2000000) & (city_frame['name'].str.contains('m'))]
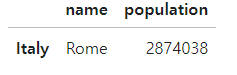
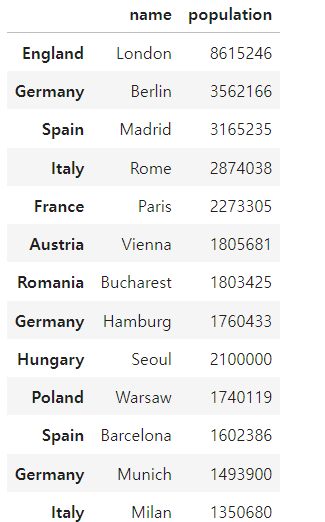
city_frame.loc['Hungary']=['Seoul',2100000]
city_frame
city_frame.loc['Germany','population']
Germany 3562166
Germany 1760433
Germany 1493900
Name: population, dtype: int64
city_frame.iloc[0, 1]
8615246
city_frame.iloc[1:3, 0:3]
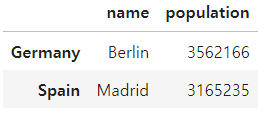
city_frame.iloc[[0,2,4,6],1]
England 8615246
Spain 3165235
France 2273305
Romania 1803425
Name: population, dtype: int64
city_frame.iloc[1:6,1]
Germany 3562166
Spain 3165235
Italy 2874038
France 2273305
Austria 1805681
Name: population, dtype: int64
합(sum) and 누적합(cumulative sum)
years = range(2014, 2019)
cities = ["Zürich", "Freiburg", "München", "Konstanz", "Saarbrücken"]
shops = pd.DataFrame(index=years)
for city in cities:
shops.insert(loc=len(shops.columns),
column=city,
value=(np.random.uniform(0.7, 1, (5,)) * 1000).round(2))
print(shops)
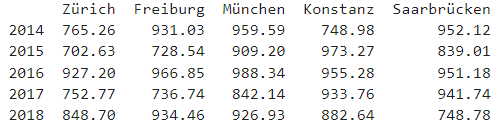
shops.sum(axis = 0)
Zürich 3996.56
Freiburg 4297.62
München 4626.20
Konstanz 4493.93
Saarbrücken 4432.83
dtype: float64
shops.sum(axis = 1)
2014 4356.98
2015 4152.65
2016 4788.85
2017 4207.15
2018 4341.51
dtype: float64
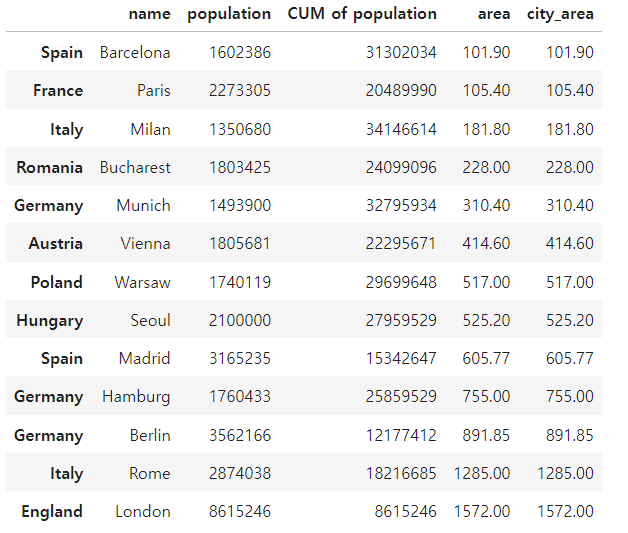
city_frame['CUM of population'] = city_frame['population'].cumsum()
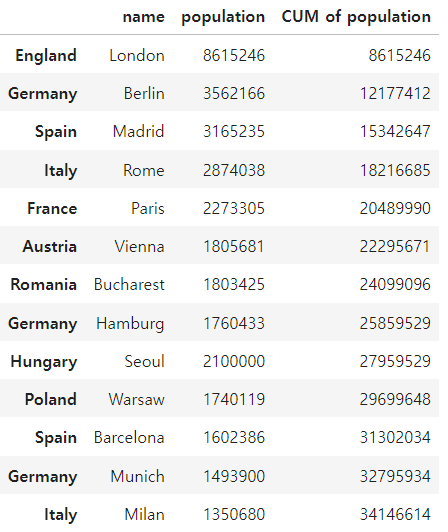
정렬
- DataFrame.sort_values(by, *, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
city_frame.sort_values(by='city_area', ascending=False)
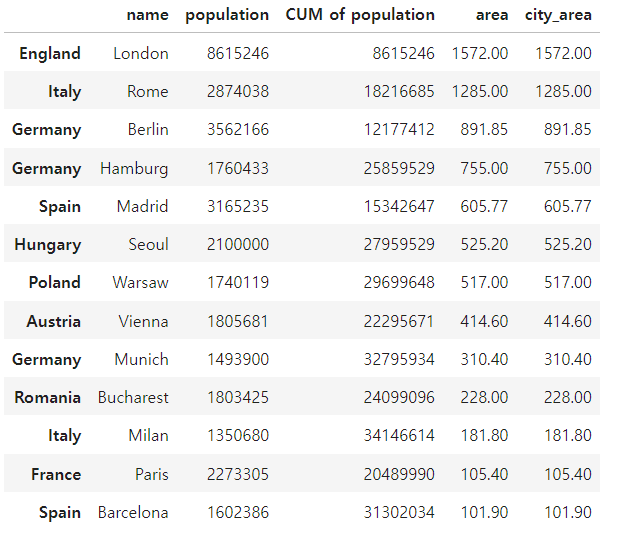
city_frame.sort_values(by='city_area')
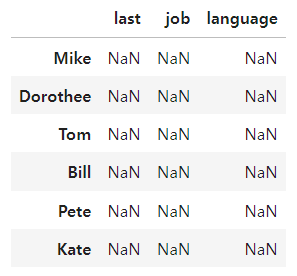
dataframes 대체값 설정
import pandas as pd
first = ('Mike', 'Dorothee', 'Tom', 'Bill', 'Pete', 'Kate')
last = ('Meyer', 'Maier', 'Meyer', 'Mayer', 'Meyr', 'Mair')
job = ('data analyst', 'programmer', 'computer scientist','data scientist',
'accountant', 'psychiatrist')
language = ('Python', 'Perl', 'Java', 'Java', 'Cobol', 'Brainfuck')
df = pd.DataFrame(columns= ['last','job','language'],
index = first
)
df
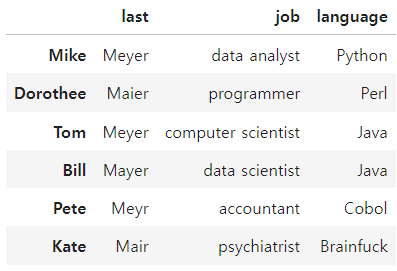
list(zip(last, job, language))
[('Meyer', 'data analyst', 'Python'),
('Maier', 'programmer', 'Perl'),
('Meyer', 'computer scientist', 'Java'),
('Mayer', 'data scientist', 'Java'),
('Meyr', 'accountant', 'Cobol'),
('Mair', 'psychiatrist', 'Brainfuck')]
df[['last','job','language']] = list(zip(last, job, language))
df
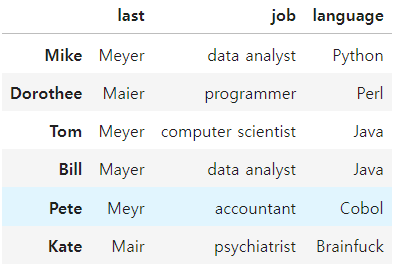
dataframe 값 대체
# Bill의 job에 access
df.loc['Bill','job']
# Bill의 job을 data_analyst change
df.loc['Bill','job'] = 'data analyst'
df
#pete의 language 를 python으로
df.loc['pete','job'] = 'Python'
df
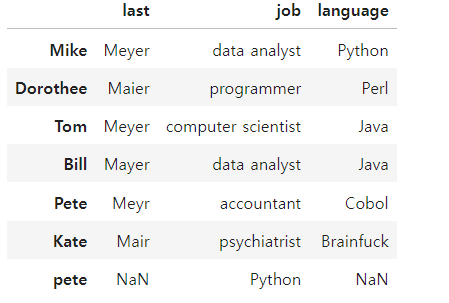
- at
df.at['Pete','job'] = 'data analyst'
재배치 - replace()
- DataFrame.replace(to_replace=None, value=_NoDefault.no_default, *, inplace=False, limit=None, regex=False, method=_NoDefault.no_default)
df = pd.DataFrame({'A': [0, 1, 2, 3, 4],
'B': [5, 6, 7, 8, 9],
'C': ['a', 'b', 'c', 'd', 'e']})
df

df.replace(0,5)

df.replace([0, 1, 2, 3], 4, inplace = True)

df.replace(4,6)S

import pandas as pd
first = ('Mike', 'Dorothee', 'Tom', 'Bill', 'Pete', 'Kate')
last = ('Meyer', 'Maier', 'Meyer', 'Mayer', 'Meyr', 'Mair')
job = ('data analyst', 'programmer', 'computer scientist','data scientist',
'accountant', 'psychiatrist')
language = ('Python', 'Perl', 'Java', 'Java', 'Cobol', 'Brainfuck')
df = pd.DataFrame(columns= ['first','job','language'],
index = last
)
df[['first','job','language']] = list(zip(first, job, language))
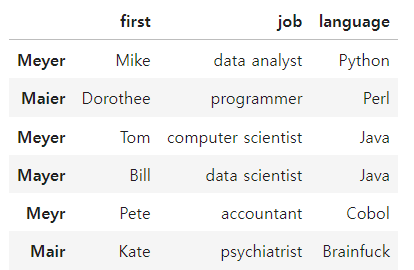
# Mike는 Michael , Tom 은 Thomas, Perl은 Python
df.replace(['Mike','Tom','Perl'], ['Michael','Thomas','Python'], inplace = True)
df
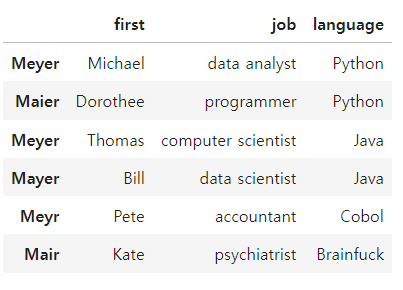
정규화
df = pd.DataFrame(list(zip(first, last, job, language)),
columns =['first', 'last', 'job', 'language'])
df.replace(['Cobol'],['Pythen'],inplace = True)
df
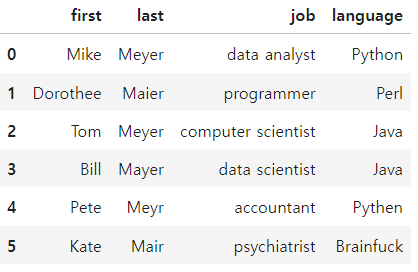
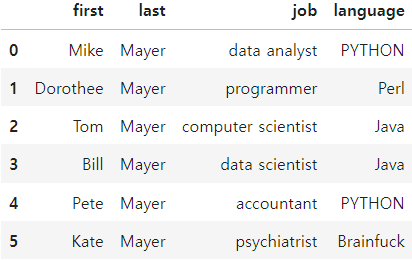
df.replace(to_replace = [r'M[ea][iy]e?r',r'P[iy]th[eo]n'],value = ['Mayer','PYTHON'],regex = True, inplace = True)
df
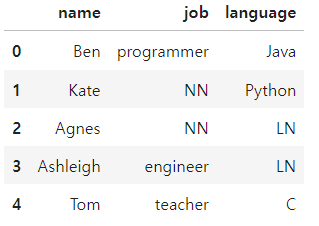
import pandas as pd
df = pd.DataFrame({
'name':['Ben', 'Kate', 'Agnes', 'Ashleigh', 'Tom'],
'job':['programmer', 'NN', 'NN', 'engineer', 'teacher'],
'language':['Java', 'Python', 'LN', 'LN', 'C']})
df
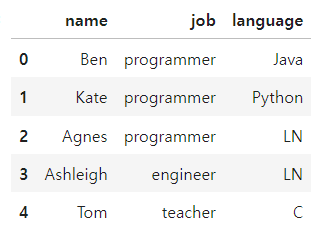
df.replace(to_replace = 'NN',
method = 'ffill'
)
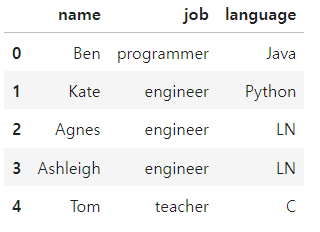
df.replace(to_replace = 'NN',
method = 'bfill'
)
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
df
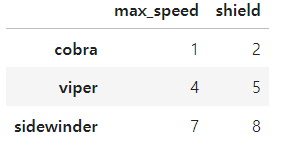
df[[True,False,True]]

Groupby
pandas.Series.groupby()
- Series.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)[source]
import pandas as pd
import numpy as np
import random
nvalues = 30
# we create random values, which will be used as the Series values:
values = np.random.randint(1, 20, (nvalues,))
fruits = ["bananas", "oranges", "apples", "clementines", "cherries", "pears"]
fruits_index = np.random.choice(fruits, (nvalues,))
s = pd.Series(values, index=fruits_index)
s.index
Index(['bananas', 'cherries', 'oranges', 'apples', 'cherries', 'bananas', 'pears', 'clementines', 'cherries', 'pears', 'bananas', 'clementines', 'apples', 'cherries', 'apples', 'clementines', 'cherries', 'pears', 'apples', 'apples', 'oranges', 'apples', 'clementines', 'pears', 'clementines', 'oranges', 'oranges', 'bananas', 'clementines', 'oranges'], dtype='object')
grouped = s.groupby(s.index)
<pandas.core.groupby.generic.SeriesGroupBy object at 0x0000023550E550D0>
for fruit, s_obj in grouped:
#print(fruit)
print(f'============={fruit}============')
print(s_obj)
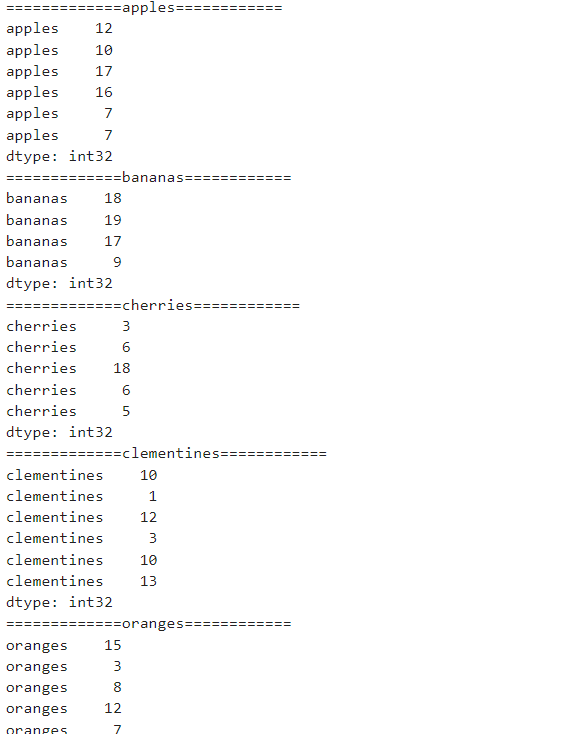
Groupby with Dataframe
- pandas.DataFrame.groupby ()
- DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)
import pandas as pd
beverages = pd.DataFrame({'Name': ['Robert', 'Melinda', 'Brenda',
'Samantha', 'Melinda', 'Robert',
'Melinda', 'Brenda', 'Samantha'],
'Coffee': [3, 0, 2, 2, 0, 2, 0, 1, 3],
'Tea': [0, 4, 2, 0, 3, 0, 3, 2, 0]})
beverages
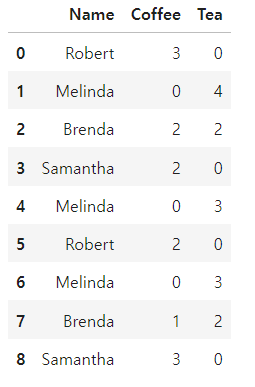
beverages.groupby(['Name'])
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002354DCBBB10>
res = beverages.groupby(['Name']).sum()
res
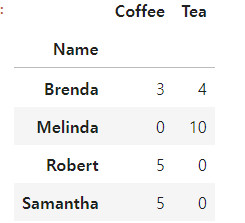
beverages.groupby(['Name']).mean()
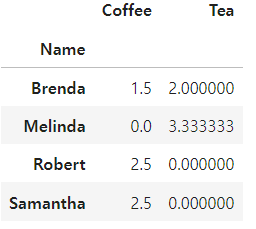
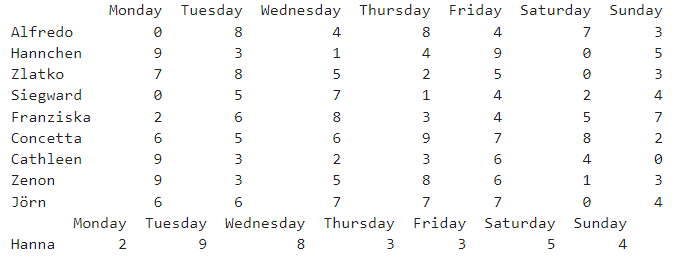
- faker : 가짜 데이터 만들어주는 모듈
from faker import Faker
import numpy as np
from itertools import chain
fake = Faker('de_DE')
number_of_names = 10
names = []
for _ in range(number_of_names):
names.append(fake.first_name())
data = {}
workweek = ("Monday", "Tuesday", "Wednesday", "Thursday", "Friday")
weekend = ("Saturday", "Sunday")
for day in chain(workweek, weekend):
data[day] = np.random.randint(0, 10, (number_of_names,))
data_df = pd.DataFrame(data, index=names)
data_df
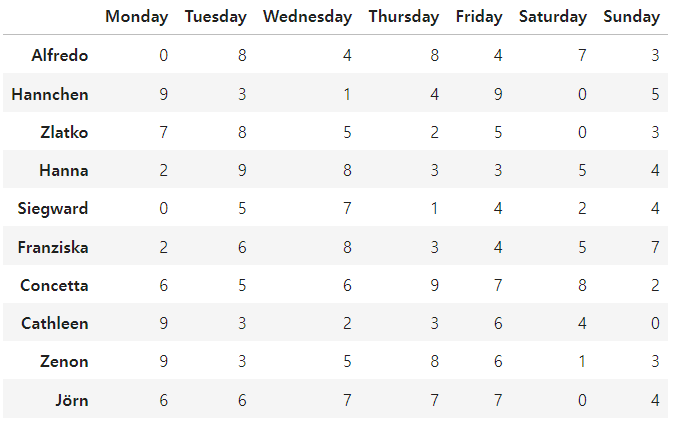
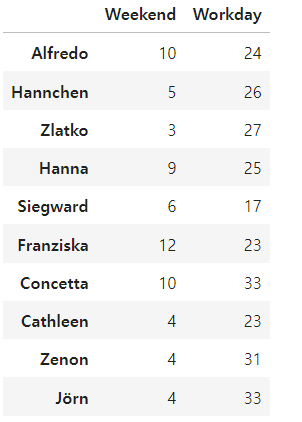
def is_weekend(day):
if day in ['Saturday', 'Sunday']:
return 'Weekend'
else:
return 'Workday'
data_df.groupby(by=is_weekend, axis =1).sum()
def is_name_Hanna(name):
if name == 'Hanna':
return 'hello'
else:
return 'anHello'
data_df.groupby(by=is_name_Hanna).sum()

for res_func, df in data_df.groupby(by=is_name_Hanna):
print(df)