
4.8. 연도 별 분석
merged_order_payment_year = merged_order_payment_date[['year', 'payment_value']].copy()
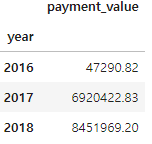
merged_order_payment_year

merged_order_payment_year = merged_order_payment_year.groupby('year').sum()
merged_order_payment_year.head()
merged_order_payment_year.iplot(kind='bar', theme='white')
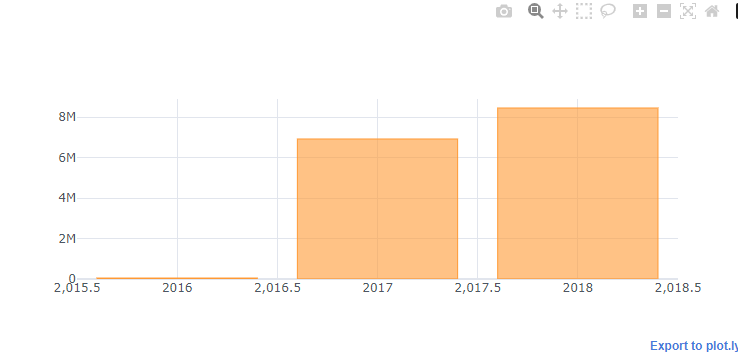
은근히 x tick 제어가 필요할 때가 꽤 있음
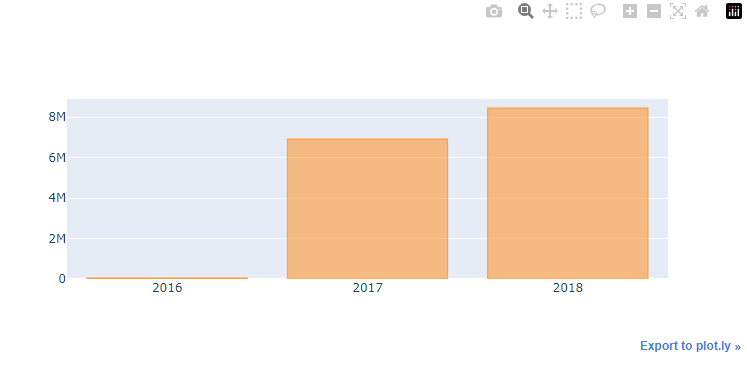
layout = {
'xaxis': {
'showticklabels':True,
'tickvals':[2016, 2017, 2018]
}
}
merged_order_payment_year.iplot(kind='bar', theme='white', layout=layout)
4.9. 요일 별 분석
- weekday : (0:월, 1:화, 2:수, 3:목, 4:금, 5:토, 6:일)
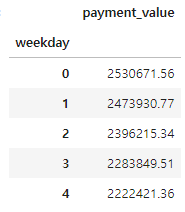
merged_order_payment_weekday = merged_order_payment_date[['weekday', 'payment_value']].copy()
merged_order_payment_weekday = merged_order_payment_weekday.groupby('weekday').sum()
merged_order_payment_weekday.head()
merged_order_payment_weekday = merged_order_payment_weekday.reset_index()
merged_order_payment_weekday.head()

apply() 함수 활용해서 컬럼값 변경하기
- index 를 column 으로 변경하고 (reset_index()), column 값을 순서에 맞춰서 변경 후, index로 재설정(set_index())
def func(row):
if row['weekday'] == 0:
row['weekday'] = 'Mon'
elif row['weekday'] == 1:
row['weekday'] = 'Tue'
elif row['weekday'] == 2:
row['weekday'] = 'Wed'
elif row['weekday'] == 3:
row['weekday'] = 'Thu'
elif row['weekday'] == 4:
row['weekday'] = 'Fri'
elif row['weekday'] == 5:
row['weekday'] = 'Sat'
elif row['weekday'] == 6:
row['weekday'] = 'Sun'
return row
merged_order_payment_weekday = merged_order_payment_weekday.apply(func, axis=1)
merged_order_payment_weekday

merged_order_payment_weekday = merged_order_payment_weekday.set_index('weekday')
merged_order_payment_weekday.iplot(kind='bar', theme='white')

4.10. 계절 별(quarter별) 분석
- quarter : (1:1분기, 2:2분기, 3:3분기, 4:4분기)
물론 현지 사정에 따라 계절 상황을 알면 도움이 됨
merged_order_payment_quarter = merged_order_payment_date[['quarter', 'payment_value']].copy()
merged_order_payment_quarter = merged_order_payment_quarter.groupby('quarter').sum()
merged_order_payment_quarter.head()

merged_order_payment_quarter = merged_order_payment_quarter.reset_index()
def func(row):
if row['quarter'] == 1:
row['quarter'] = '1Q'
elif row['quarter'] == 2:
row['quarter'] = '2Q'
elif row['quarter'] == 3:
row['quarter'] = '3Q'
elif row['quarter'] == 4:
row['quarter'] = '4Q'
return row
merged_order_payment_quarter = merged_order_payment_quarter.apply(func, axis=1)
merged_order_payment_quarter = merged_order_payment_quarter.set_index('quarter')
merged_order_payment_quarter.iplot(kind='bar', theme='white')
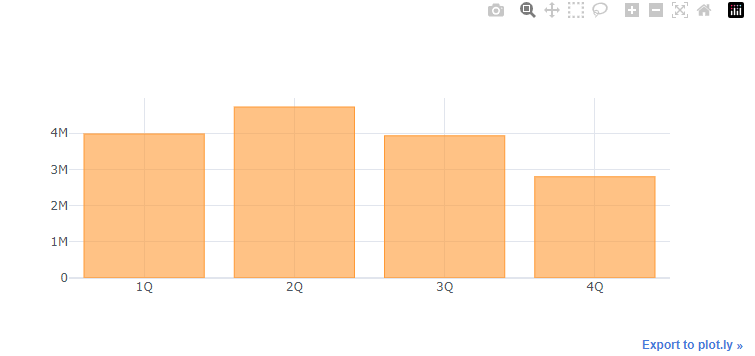
4.11. 시간 별 분석
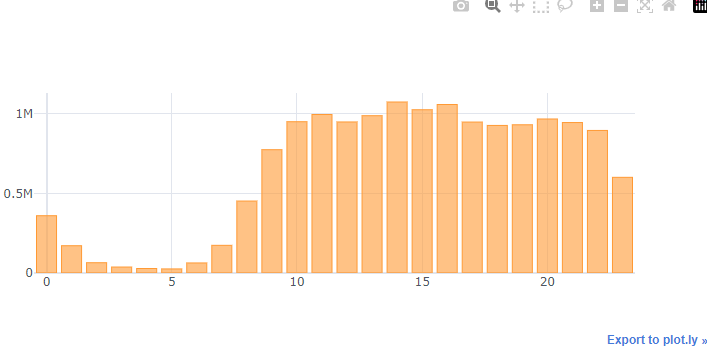
분명히 시간대별 구매율이 높은 구간이 있을 것임
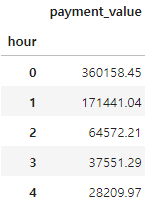
merged_order_payment_hour = merged_order_payment_date[['hour', 'payment_value']].copy()
merged_order_payment_hour = merged_order_payment_hour.groupby('hour').sum()
merged_order_payment_hour.head()
merged_order_payment_hour.iplot(kind='bar', theme='white')
layout = {
'xaxis': {
'showticklabels':True,
'dtick': 1
}
}
merged_order_payment_hour.iplot(kind='bar', theme='white', layout=layout)

4.12. 분(minutes)별 분석
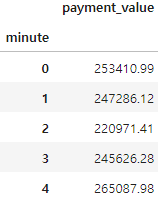
merged_order_payment_minute = merged_order_payment_date[['minute', 'payment_value']].copy()
merged_order_payment_minute = merged_order_payment_minute.groupby('minute').sum()
merged_order_payment_minute.head()
merged_order_payment_minute.iplot(kind='bar', theme='white')

layout = {
'xaxis': {
'showticklabels':True,
'dtick': 1
}
}
merged_order_payment_minute.iplot(kind='bar', theme='white', layout=layout)
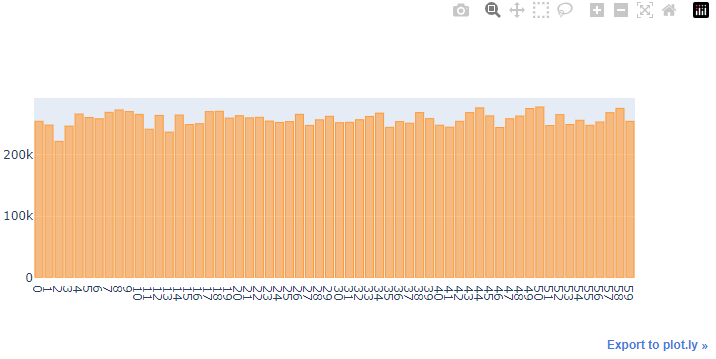
4.13. 요일/시간 간 거래액 상관관계
상관관계 분석을 위해 사용되는 그래프: heatmap
import pandas as pd
PATH = "00_data/"
products = pd.read_csv(PATH + "olist_products_dataset.csv", encoding='utf-8-sig')
customers = pd.read_csv(PATH + "olist_customers_dataset.csv", encoding='utf-8-sig')
geolocation = pd.read_csv(PATH + "olist_geolocation_dataset.csv", encoding='utf-8-sig')
order_items = pd.read_csv(PATH + "olist_order_items_dataset.csv", encoding='utf-8-sig')
payments = pd.read_csv(PATH + "olist_order_payments_dataset.csv", encoding='utf-8-sig')
reviews = pd.read_csv(PATH + "olist_order_reviews_dataset.csv", encoding='utf-8-sig')
orders = pd.read_csv(PATH + "olist_orders_dataset.csv", encoding='utf-8-sig')
sellers = pd.read_csv(PATH + "olist_sellers_dataset.csv", encoding='utf-8-sig')
category_name = pd.read_csv(PATH + "product_category_name_translation.csv", encoding='utf-8-sig')
orders = orders.dropna()
merged_order = pd.merge(orders, payments, on='order_id')
merged_order_payment_date = merged_order[['order_purchase_timestamp', 'payment_value']].copy()
merged_order_payment_date['order_purchase_timestamp'] = pd.to_datetime(merged_order_payment_date['order_purchase_timestamp'], format='%Y-%m-%d %H:%M:%S', errors='raise')
merged_order_payment_date['year'] = merged_order_payment_date['order_purchase_timestamp'].dt.year
merged_order_payment_date['monthday'] = merged_order_payment_date['order_purchase_timestamp'].dt.day
merged_order_payment_date['weekday'] = merged_order_payment_date['order_purchase_timestamp'].dt.weekday
merged_order_payment_date['month'] = merged_order_payment_date['order_purchase_timestamp'].dt.month
merged_order_payment_date['hour'] = merged_order_payment_date['order_purchase_timestamp'].dt.hour
merged_order_payment_date['quarter'] = merged_order_payment_date['order_purchase_timestamp'].dt.quarter
merged_order_payment_date['minute'] = merged_order_payment_date['order_purchase_timestamp'].dt.minute
merged_order_payment_date.head()

merged_order_payment_hour_weekday = merged_order_payment_date[['weekday', 'hour', 'payment_value']].copy()
merged_order_payment_hour_weekday
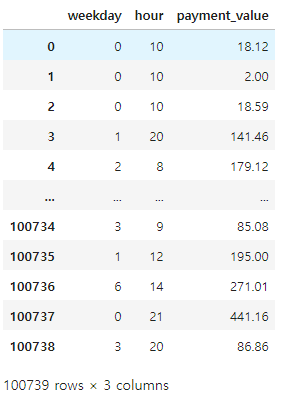
weekday 를 요일명으로 변경하기
멀티 인덱스: 하나 이상의 컬럼을 인덱스로 설정할 수 있음
merged_order_payment_hour_weekday = merged_order_payment_hour_weekday.groupby(['weekday','hour']).sum()
merged_order_payment_hour_weekday
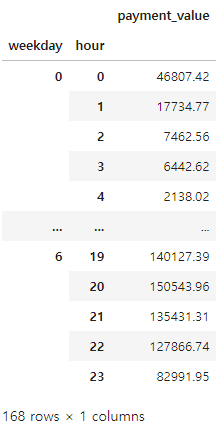
멀티 인덱스에서 특정 인덱스값 가져오기
merged_order_payment_hour_weekday.index[1][0] # 리스트 안의 리스트일 때처럼 가리키면 됨0
merged_order_payment_hour_weekday = merged_order_payment_hour_weekday.reset_index()
merged_order_payment_hour_weekday
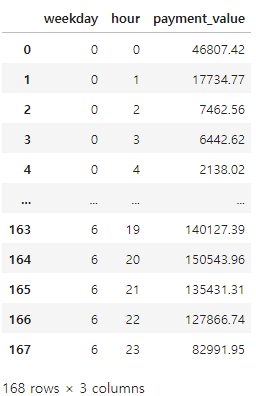
apply 함수 만들기
def func(row):
if row['weekday'] == 0:
row['weekday'] = 'Sun'
elif row['weekday'] == 1:
row['weekday'] = 'Mon'
elif row['weekday'] == 2:
row['weekday'] = 'Tue'
elif row['weekday'] == 3:
row['weekday'] = 'Wed'
elif row['weekday'] == 4:
row['weekday'] = 'Thu'
elif row['weekday'] == 5:
row['weekday'] = 'Fri'
elif row['weekday'] == 6:
row['weekday'] = 'Sat'
return row
merged_order_payment_hour_weekday = merged_order_payment_hour_weekday.apply(func, axis=1)
merged_order_payment_hour_weekday
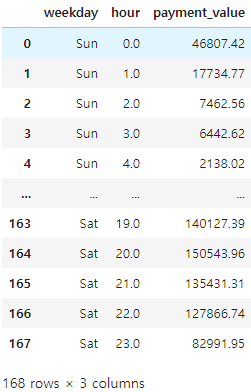
행 임의 이름 순서로 정렬하기
- 우선 해당 이름에 번호를 매겨 놓은 후, sort_values 로 번호를 기반으로 값으로 정렬함
해당데이터프레임Series= pd.Categorical(시리즈데이터, categories=이름순서리스트, ordered=True)
merged_order_payment_hour_weekday['weekday'] = pd.Categorical(merged_order_payment_hour_weekday['weekday'],categories=['Mon','Tue','Wed','Thu','Fri','Sat','Sun'],ordered=True)
행 값으로 정렬하기
sort_values(by=[필드명])
merged_order_payment_hour_weekday = merged_order_payment_hour_weekday.sort_values(by=['weekday', 'hour'], ascending=True)
merged_order_payment_hour_weekday.head(40)

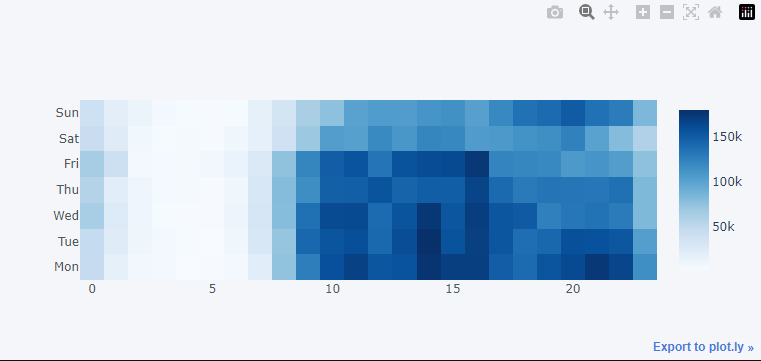
merged_order_payment_hour_weekday.iplot(kind='heatmap', y='weekday', x='hour', z='payment_value', colorscale='Blues')
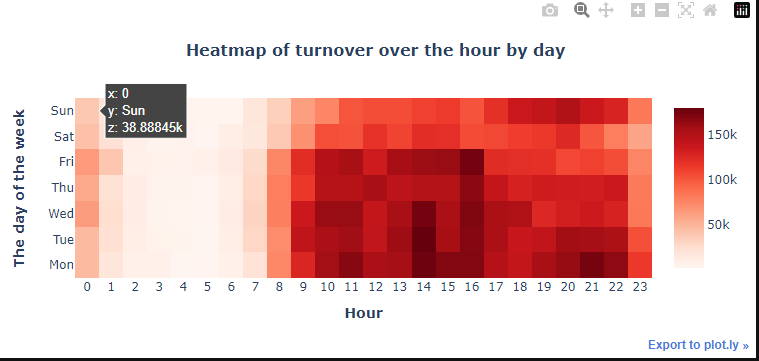
layout = {
'title': {
"text": "<b>Heatmap of turnover over the hour by day</b>",
"x": 0.5,
"y": 0.87,
"font": {
"size": 16
}
},
'xaxis': {
'title': '<b>Hour</b>',
'showticklabels':True,
'dtick': 1
},
"yaxis": {
"title": "<b>The day of the week</b>"
},
"template":'plotly_white'
}
merged_order_payment_hour_weekday.iplot(kind='heatmap', y='weekday', x='hour', z='payment_value', colorscale='Reds', layout=layout)
5. 어떤 카테고리가 가장 많은 상품이 팔렸을까?
1. 카테고리별 판매 분석
import pandas as pd
PATH = "00_data/"
products = pd.read_csv(PATH + "olist_products_dataset.csv", encoding='utf-8-sig')
customers = pd.read_csv(PATH + "olist_customers_dataset.csv", encoding='utf-8-sig')
geolocation = pd.read_csv(PATH + "olist_geolocation_dataset.csv", encoding='utf-8-sig')
order_items = pd.read_csv(PATH + "olist_order_items_dataset.csv", encoding='utf-8-sig')
payments = pd.read_csv(PATH + "olist_order_payments_dataset.csv", encoding='utf-8-sig')
reviews = pd.read_csv(PATH + "olist_order_reviews_dataset.csv", encoding='utf-8-sig')
orders = pd.read_csv(PATH + "olist_orders_dataset.csv", encoding='utf-8-sig')
sellers = pd.read_csv(PATH + "olist_sellers_dataset.csv", encoding='utf-8-sig')
category_name = pd.read_csv(PATH + "product_category_name_translation.csv", encoding='utf-8-sig')
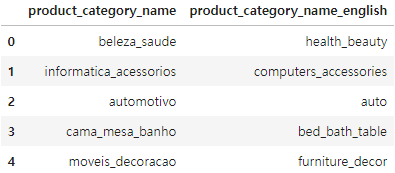
products 와 category_name 합치기
products.head()

category_name.head()
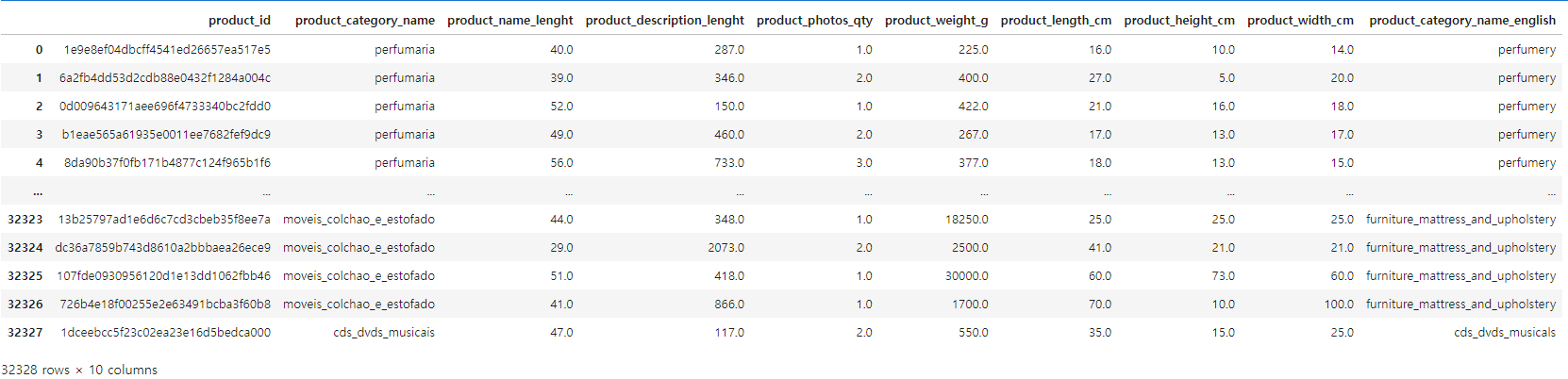
products_category = pd.merge(products, category_name, on='product_category_name')
products_category
필요한 컬럼만 가져오기
products_category_only = products_category[['product_id', 'product_category_name_english']].copy()
products_category_only.head()
order_items.isnull().sum()

order_items.head()

products_category_order = pd.merge(products_category_only, order_items, on='product_id')
products_category_order.head()

2. 카테고리별 거래 건수 확인하기
- 카테고리 이름으로 grouping 한다: products_category_order.groupby('product_category_name_english')
- grouping 할 때 order는 거래액이 아니라 거래 건수로 count 를 한다: .aggregate({'order_id':'count'})
- .aggregate() 또는 .agg() 를 사용
- 거래 건수로 count 한 값의 컬럼 명을 order_count 로 바꾼다: .rename(columns={'order_id':'order_count'})
products_category_order = products_category_order.groupby('product_category_name_english').aggregate({'order_id':'count'}).rename(columns={'order_id':'order_count'})
products_category_order.head()

import chart_studio.plotly as py
import cufflinks as cf
cf.go_offline(connected=True)
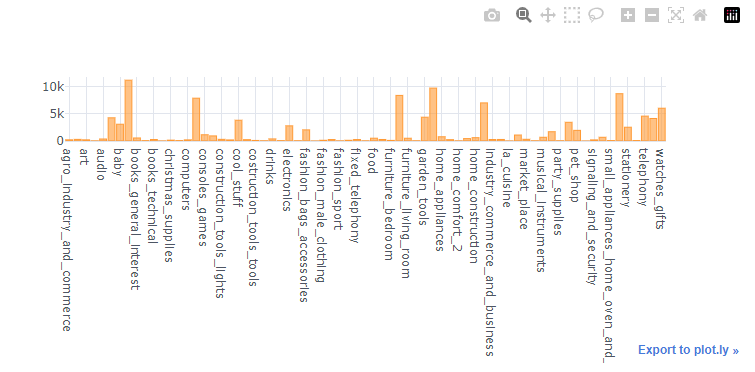
products_category_order.iplot(kind='bar', theme='white')
plotly Ficture 객체로 그래프 그려보기
카테고리별 거래건수로 정렬하기
products_category_order = products_category_order.sort_values(by='order_count',ascending=False)
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(
go.Bar(
x=products_category_order.index,
y=products_category_order['order_count']
)
)
fig.update_layout(
{
"title": {
"text": "<b>The number of Order per Category in Brazilian Olist E-Commerce company</b>",
"x": 0.5,
"y": 0.9,
"font": {
"size": 15
}
},
"xaxis": {
"title": "from Oct. 2016 to Sep. 2018",
"showticklabels":True,
"tickfont": {
"size": 7
}
},
"yaxis": {
"title": "The number of Order"
},
"template":'plotly_white'
}
)
fig.show()
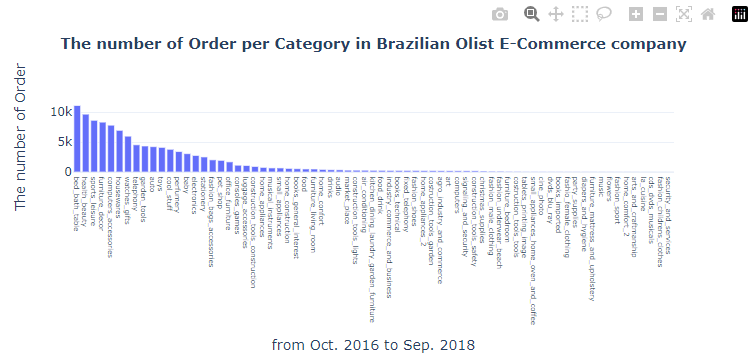
주요 카테고리만 확인하기
products_category_order = products_category_order[products_category_order['order_count'] > 1000]
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(
go.Bar(
x=products_category_order.index,
y=products_category_order['order_count']
)
)
fig.update_layout(
{
"title": {
"text": "<b>The number of Order per Category in Brazilian Olist E-Commerce company</b>",
"x": 0.5,
"y": 0.9,
"font": {
"size": 15
}
},
"xaxis": {
"title": "from Oct. 2016 to Sep. 2018",
"showticklabels":True,
"tickfont": {
"size": 7
}
},
"yaxis": {
"title": "The number of Order"
},
"template":'plotly_white'
}
)
fig.show()
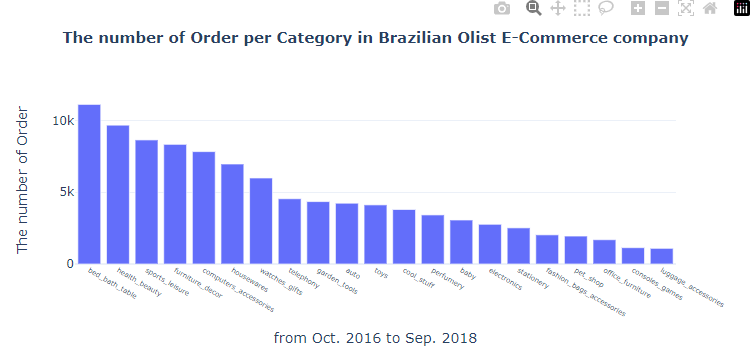
6. 평균 배송 시간은?
1. 평균 배송 시간 분석
import pandas as pd
PATH = "00_data/"
products = pd.read_csv(PATH + "olist_products_dataset.csv", encoding='utf-8-sig')
customers = pd.read_csv(PATH + "olist_customers_dataset.csv", encoding='utf-8-sig')
geolocation = pd.read_csv(PATH + "olist_geolocation_dataset.csv", encoding='utf-8-sig')
order_items = pd.read_csv(PATH + "olist_order_items_dataset.csv", encoding='utf-8-sig')
payments = pd.read_csv(PATH + "olist_order_payments_dataset.csv", encoding='utf-8-sig')
reviews = pd.read_csv(PATH + "olist_order_reviews_dataset.csv", encoding='utf-8-sig')
orders = pd.read_csv(PATH + "olist_orders_dataset.csv", encoding='utf-8-sig')
sellers = pd.read_csv(PATH + "olist_sellers_dataset.csv", encoding='utf-8-sig')
category_name = pd.read_csv(PATH + "product_category_name_translation.csv", encoding='utf-8-sig')
orders.head()

결측치 갯수 확인하기
orders.info()

orders.isnull().sum()
결측치가 있는 행 삭제하기
orders = orders.dropna()
orders.isnull().sum()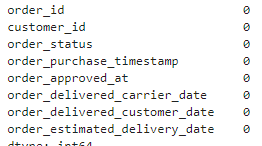
배송 시간을 계산해서 새로운 컬럼으로 추가
- 시간 차는 timedelta64 타입으로 표시됨
orders['delivery_time'] = pd.to_datetime(orders['order_delivered_customer_date']) - pd.to_datetime(orders['order_purchase_timestamp'])
orders.info()
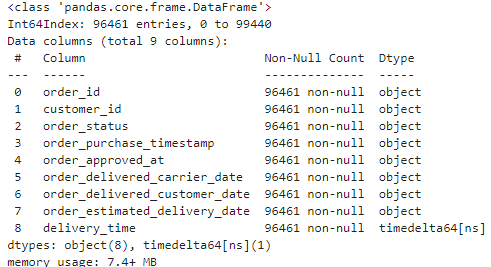
2. 통계 활용
- 데이터가 주어졌을 때, 데이터 이해를 위해 가벼운 통계 기법을 사용
- 대표적인 예가 평균을 구하는 것임, 이외에 표준편차(std), 최소값(min), 사분위수(25%, 50%, 75%), 최대값(max)
- 데이터에 따라 보다 알맞은 대표값을 구하기 위해, 평균 이외에 다양한 기법이 존재함
- 가중 평균
- 데이터값(xi) X 가중치(wi) 의 총 합을 다시 가중치(wi)의 총합으로 나눈 것
- 예: 여러 기기로부터 가져온 데이터 중, 특정 기기는 신뢰도가 떨어질 경우, 해당 기기로부터 나온 데이터에는 가중치를 낮게 줌
- 중간값 (가중중간값도 가능)
- 데이터를 정렬한 후 중간에 위치한 값을 취함
- 평균은 특잇값(outlier)에 큰 영향을 받으므로, 특잇값에 큰 영향을 받지 않도록 중간값을 활용할 수 있음
- 절사평균
- 데이터를 정렬한 후, 양끝에서 일정 개수의 값들을 빼고, 남은 데이터를 기반으로 평균을 계산
- 즉, 특잇값을 평균을 구할 때 제외하는 것임
orders['delivery_time'].describe() - 가중 평균
2.1. boxplot 그래프로 특잇값의 정도 확인해보기
import chart_studio.plotly as py
import cufflinks as cf
cf.go_offline(connected=True)
orders['delivery_time'].iplot(kind="box")
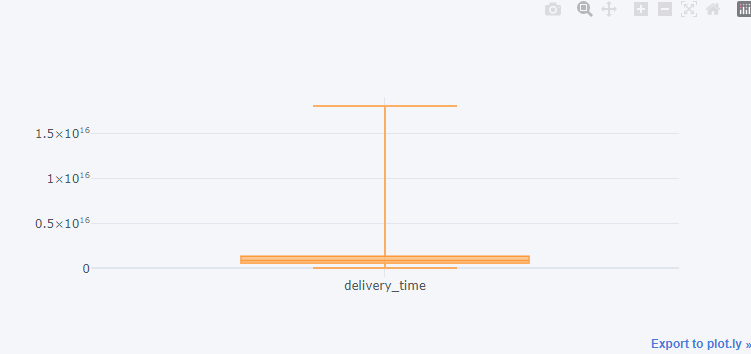
2.2. 상위에 있는 특잇값이 문제이므로, 0 ~ 95%에 해당하는 데이터만 사용해서 평균을 계산하기로 함
- pandas에서는 quantile() 함수를 제공
- 입력은 0 ~ 1 사이의 값으로, .95 는 95%에 해당하는 값을 의미
delivery_time_q95 = orders['delivery_time'].quantile(.95)
delivery_time_q95
Timedelta('29 days 06:36:33')
delivery_time_q90 = orders['delivery_time'].quantile(.90)
delivery_time_q90
Timedelta('23 days 02:21:07')
orders = orders[orders['delivery_time'] < delivery_time_q95]
orders.info()
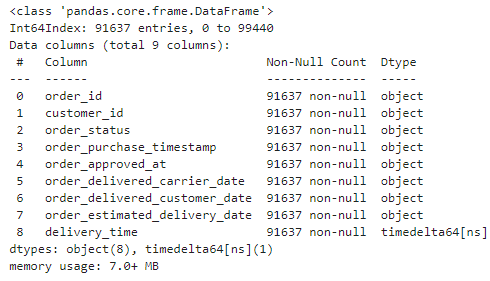
orders['delivery_time'].describe()
3. 월별 평균 배송 시간 분석
- orders_date['delivery_time'].dt.total_seconds() : 배송 시간을 초로 변환
- float 타입으로 변환해서, mean() 평균 계산
orders_date = orders[['order_purchase_timestamp', 'delivery_time']].copy()
# order_purchase_timestamp 의 날짜 데이터를 기반으로 월별 계산을 해야 하므로 datetime 타입으로 변환
orders_date['order_purchase_timestamp'] = pd.to_datetime(orders_date['order_purchase_timestamp'], format='%Y-%m-%d %H:%M:%S', errors='raise')
# delivery_time이 timedelta64 타입인데, 이를 float 타입으로 변환
orders_date['delivery_time'] = orders_date['delivery_time'].dt.total_seconds()
orders_date = orders_date.set_index('order_purchase_timestamp')
orders_date.info()
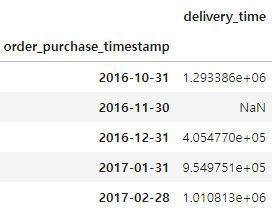
orders_date = orders_date.groupby(pd.Grouper(freq='M')).mean() # key 는 기본이 index 임
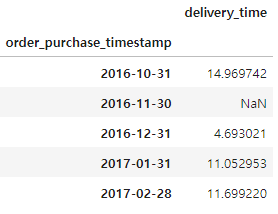
orders_date.head()
일 단위로 배송 시간 변환
- 1일은 86400초
orders_date['delivery_time'] = orders_date['delivery_time'] / 86400
orders_date.head()
import chart_studio.plotly as py
import cufflinks as cf
cf.go_offline(connected=True)
orders_date.iplot(kind="bar")
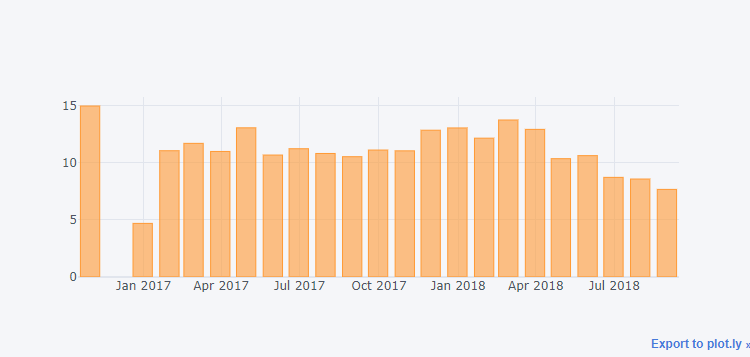
orders_date = orders_date[orders_date.index > "2017-01-01"]
layout = {
'xaxis': {
'showticklabels':True,
"tick0": "2017-01-31",
'dtick': 'M1',
"tickfont": {
"size": 7
}
}
}
orders_date.iplot(kind="bar", layout=layout)
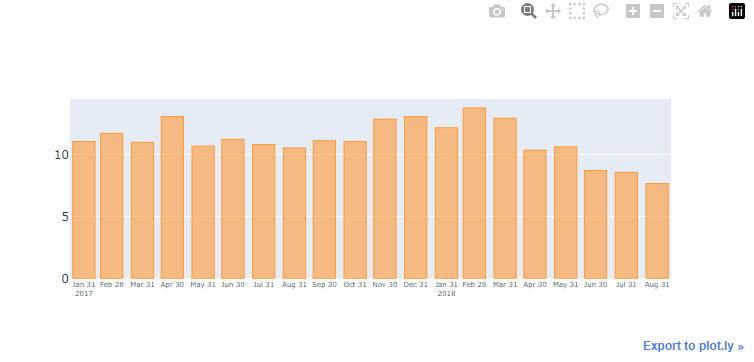
plotly 로 세부적인 부분까지 수정해보기
colors = ['#1B80BF',] * len(orders_date.index)
for index in range(15, len(orders_date.index)):
colors[index] = '#BF2C47'
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(
go.Bar(
x=orders_date.index,
y=orders_date['delivery_time'],
text=orders_date['delivery_time'],
textposition='auto',
texttemplate='%{text:.2f} days',
marker_color=colors
)
)
fig.update_layout(
{
"title": {
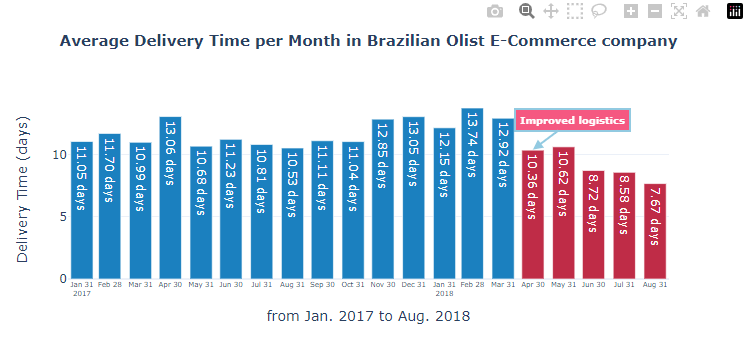
"text": "<b>Average Delivery Time per Month in Brazilian Olist E-Commerce company</b>",
"x": 0.5,
"y": 0.9,
"font": {
"size": 15
}
},
"xaxis": {
"title": "from Jan. 2017 to Aug. 2018",
"showticklabels":True,
"tick0": "2017-01-31",
"dtick": "M1",
"tickfont": {
"size": 7
}
},
"yaxis": {
"title": "Delivery Time (days)"
},
"template":'plotly_white'
}
)
fig.add_annotation(
x="2018-04-30",
y=10.4,
text="<b>Improved logistics</b>",
showarrow=True,
font=dict(
size=10,
color="#ffffff"
),
align="center",
arrowhead=2,
arrowsize=1,
arrowwidth=2,
arrowcolor="#77BDD9",
ax=40,
ay=-30,
bordercolor="#77BDD9",
borderwidth=2,
borderpad=4,
bgcolor="#F22E62",
opacity=0.8
)
fig.show()
'빅데이터 분석가 양성과정 > Python' 카테고리의 다른 글
| 데이터 인코딩 (0) | 2024.07.10 |
|---|---|
| 결측값 처리 (0) | 2024.07.10 |
| pandas - brazil ecommerce dataset ( 1 ) (0) | 2024.07.09 |
| pandas_COVID-19 ( 3 ) (0) | 2024.07.09 |
| pandas_COVID-19 ( 2 ) (0) | 2024.07.09 |