
철판 제고 공정데이터를 활용한 분류 모형 생성 및 성능 비교
데이터 특성
Steel Plates Faults 데이터는 1941개의 샘플을 가지며 아래의 종속변수들과 나머지 설명변수들로 구성됩니다.
- 종속변수 (7개) - 어떠한 불량이 나타났는지를 나타내고, 다음과 같습니다.
- Pastry, Z_Scratch, K_Scatch, Stains, Dirtiness, Bumps, Other_Faults
- 설명변수 (27개) - 철판의 길이, 반짝이는 정도, 두께, 타입 등 등 다양한 변수들을 가집니다.
- 첫번째 칼럼 X_Minimum ~ 27번째 칼럼 SigmoidOfAreas
- 데이터출처: https://www.kaggle.com/mahsateimourikia/faults-nna/notebooks
제조 공정 데이터의 전반적 특성
- 제조 공정 데이터는 주로 불량률을 예측하여 불량을 일으키는 원인을 제거하거나 재고를 예측하여 수요에 맞는 생산을 진행하는 등의 목적성을 가집니다.
- 다른 데이터에 비하여 데이터를 얻는 과정이 자동화되어 있는 경우가 많아 데이터 퀄리티가 높은 편이며 결측치가 적은 경향성을 가집니다.
목표
- 각 모델들의 개괄적 이해 및 구축과정 학습.
- 파라미터를 최적화 시키는 GridSearch에 대한 이해 및 코딩작업 체화.
- 각 모델의 중요 파라미터에 대한 개괄적 이해.
- 파라미터의 변화에 따른 예측력 변화 경향성 파악.
- 최적의 모형 및 파라미터를 찾는 과정에 대한 계획 수립 및 수행.
# 구글 드라이브에 내드라이브에서 폴더 생성하여 데이터를 준비하고 이를 마운트합니다.
# 계정 인증을 한 후 코드를 복사하여 붙여넣습니다.
from google.colab import drive
drive.mount('/content/drive')# 마운트가 제대로 진행되었는지 확인합니다. 아래와 같이 폴더 안에 두 데이터 파일이 포함되어 있는 것으로 출력되어야 합니다.
# file_list: ['Faults27x7_var', 'Faults.NNA']
import os
os.chdir('/content/')
path = "./drive/MyDrive/Colab Notebooks/steel"
file_list = os.listdir(path)
print ("file_list: {}".format(file_list))
import pandas as pd
import numpy as np
# 데이터를 읽어옵니다.
df = pd.read_csv("Faults.NNA", delimiter='\t', header=None)
df.head()
# 칼럼 레이블을 읽어와서 데이터 프레임의 칼럼명으로 지정합니다.
attributes_name=pd.read_csv("Faults27x7_var", delimiter=' ', header=None)
df.columns=attributes_name[0]
# 칼럼명이 제대로 지정이 되었는지 여부와 데이터 구조를 파악합니다.
df.head()
print(df.shape) # 1941, 34
#Cpu의 개수를 확인합니다.
n_cpu=os.cpu_count()
print("The number of cpus: ",n_cpu) # 2
n_thread=n_cpu*2
print("Expected number of threads:",n_thread) # 4
데이터 전처리 및 EDA
종속변수 범주화 (1) - boolean Seris로 이루어진 list 구성
## 방법 1. 논리적 연산자 &를 활용하여 생성합니다.
conditions=[(df['Pastry'] == 1) & (df['Z_Scratch'] == 0)& (df['K_Scatch'] == 0)& (df['Stains'] == 0)& (df['Dirtiness'] == 0)& (df['Bumps'] == 0)& (df['Other_Faults'] == 0),
(df['Pastry'] == 0) & (df['Z_Scratch'] == 1)& (df['K_Scatch'] == 0)& (df['Stains'] == 0)& (df['Dirtiness'] == 0)& (df['Bumps'] == 0)& (df['Other_Faults'] == 0),
(df['Pastry'] == 0) & (df['Z_Scratch'] == 0)& (df['K_Scatch'] == 1)& (df['Stains'] == 0)& (df['Dirtiness'] == 0)& (df['Bumps'] == 0)& (df['Other_Faults'] == 0),
(df['Pastry'] == 0) & (df['Z_Scratch'] == 0)& (df['K_Scatch'] == 0)& (df['Stains'] == 1)& (df['Dirtiness'] == 0)& (df['Bumps'] == 0)& (df['Other_Faults'] == 0),
(df['Pastry'] == 0) & (df['Z_Scratch'] == 0)& (df['K_Scatch'] == 0)& (df['Stains'] == 0)& (df['Dirtiness'] == 1)& (df['Bumps'] == 0)& (df['Other_Faults'] == 0),
(df['Pastry'] == 0) & (df['Z_Scratch'] == 0)& (df['K_Scatch'] == 0)& (df['Stains'] == 0)& (df['Dirtiness'] == 0)& (df['Bumps'] == 1)& (df['Other_Faults'] == 0),
(df['Pastry'] == 0) & (df['Z_Scratch'] == 0)& (df['K_Scatch'] == 0)& (df['Stains'] == 0)& (df['Dirtiness'] == 0)& (df['Bumps'] == 0)& (df['Other_Faults'] == 1)]## 방법 2. pandas.Series.astype을 활용합니다.
conditions=[df['Pastry'].astype(bool),
df['Z_Scratch'].astype(bool),
df['K_Scatch'].astype(bool),
df['Stains'].astype(bool),
df['Dirtiness'].astype(bool),
df['Bumps'].astype(bool),
df['Other_Faults'].astype(bool)]## 방법 3. pandas.Series.astype과 map, lambda를 활용합니다
# conditions_bf에 각 변수들의 Seris로 list를 구성합니다.
# conditions_bf을 사용하고 map, lambda를 활용하여 conditions_bf의 각 원소에 astype 함수를 적용합니다.
conditions_bf=[
df['Pastry'],
df['Z_Scratch'],
df['K_Scatch'],
df['Stains'],
df['Dirtiness'],
df['Bumps'],
df['Other_Faults']
]
conditions= list(map(lambda i: i.astype(bool), conditions_bf))# 잘 진행되었는지 확인합니다.
print(conditions)
print(type(conditions))
print(type(conditions[0]))
print(len(conditions))
print(len(conditions[0]))
종속변수 범주화 (2) - numpy.select를 활용한 범주화
choices = ['Pastry', 'Z_Scratch', 'K_Scatch', 'Stains', 'Dirtiness', 'Bumps','Other_Faults']
# numpy.select를 사용하고 위에 정의해드린 choices를 인수로 활용하여 범주화를 진행합니다.
df['class']=np.select(conditions,choices)
# 아래와 같이 class 칼럼이 생성되고 범주화 된 것을 확인할 수 있습니다.
df.head()
# 결측치 확인
df.isnull().sum()
EDA - 기술통계량 파악하기
# pandas.DataFrame.describe를 활용해 기술통계량을 파악합니다.
df.describe()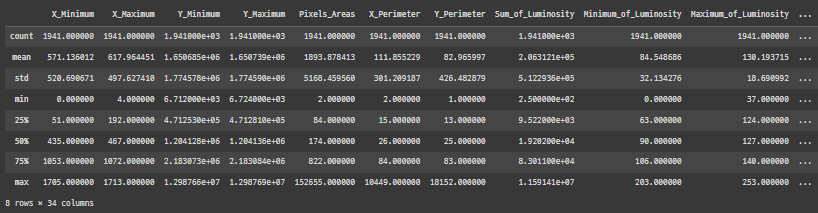
# pandas.Series.value_counts를 활용해 범주화한 종속변수의 기술통계량을 파악합니다.
df['class'].value_counts()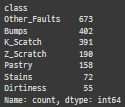
산점도를 통한 변수간의 상관관계 파악
import matplotlib.pyplot as plt
color_code = {'Pastry':'Red', 'Z_Scratch':'Blue', 'K_Scatch':'Green', 'Stains':'Black', 'Dirtiness':'Pink', 'Bumps':'Brown', 'Other_Faults':'Gold'}
# for문과 위에 정의해드린 dictionary를 활용하여 데이터의 각 행에 해당하는 color값을 지정하는 list를 생성하여 color_list에 저장합니다.
color_list = [color_code.get(i) for i in df.loc[:,'class']]
# pandas.plotting.scatter_matrix, 위에서 만든 color_list를 활용해 scatter plot을 그리고 대각원소에는 히스토그램을 출력해봅니다. figsize= [30,30], alpha=0.3,s = 50 으로 지정합니다.
pd.plotting.scatter_matrix(df.loc[:,df.columns!='class'], c=color_list, figsize= [30,30], alpha=0.3,s =50, diagonal='hist')
상관관계를 활용한 변수간의 상관관계 파악
df_corTarget = df[['X_Minimum', 'X_Maximum', 'Y_Minimum', 'Y_Maximum', 'Pixels_Areas',
'X_Perimeter', 'Y_Perimeter', 'Sum_of_Luminosity',
'Minimum_of_Luminosity', 'Maximum_of_Luminosity', 'Length_of_Conveyer',
'TypeOfSteel_A300', 'TypeOfSteel_A400', 'Steel_Plate_Thickness',
'Edges_Index', 'Empty_Index', 'Square_Index', 'Outside_X_Index',
'Edges_X_Index', 'Edges_Y_Index', 'Outside_Global_Index', 'LogOfAreas',
'Log_X_Index', 'Log_Y_Index', 'Orientation_Index', 'Luminosity_Index',
'SigmoidOfAreas']]# df_corTarget에 대하여, pandas.DataFrame.corr 을 활용해 correlation을 구한 뒤 corr에 저장.
corr=df_corTarget.corr()
corr
# heatmap을 그리기 위한 파라미터들 설정
import seaborn as sns
mask = np.zeros_like(corr)
mask[np.triu_indices_from(mask)] = True
f, ax = plt.subplots(figsize=(11, 9))
cmap = sns.diverging_palette(1,200, as_cmap=True)
# 저장해둔 corr과 mask, cmap을 활용하여 correlation을 표현하는 heatmap을 그립니다. correlation에 맞게 최대, 최소, 중간값을 지정해줍니다.
# linewidths=2로 설정합니다. 그림 크기는 figsize=(11,9)로 설정합니다.
sns.heatmap(corr,mask=mask, cmap=cmap,vmax=1,vmin=-1,center=0,linewidths=2)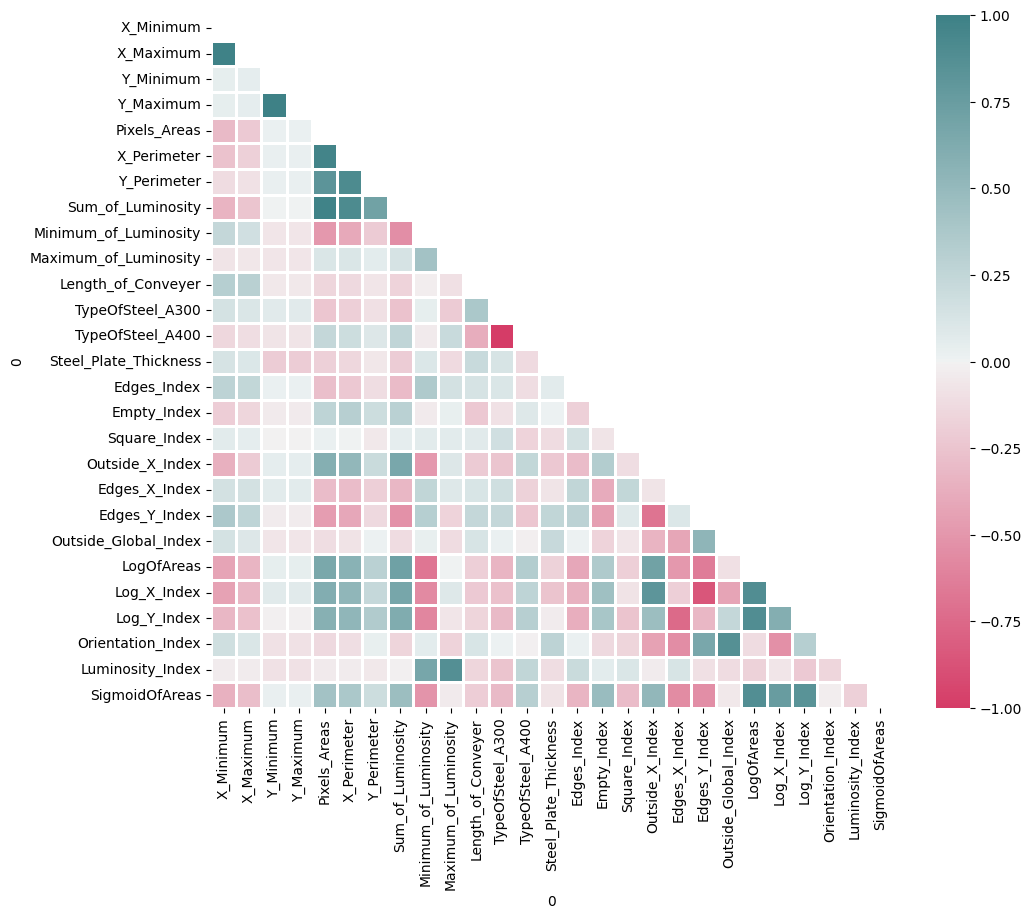
Train / Test set 분리하기
x = df[['X_Minimum', 'X_Maximum', 'Y_Minimum', 'Y_Maximum', 'Pixels_Areas',
'X_Perimeter', 'Y_Perimeter', 'Sum_of_Luminosity',
'Minimum_of_Luminosity', 'Maximum_of_Luminosity', 'Length_of_Conveyer',
'TypeOfSteel_A300', 'Steel_Plate_Thickness',
'Edges_Index', 'Empty_Index', 'Square_Index', 'Outside_X_Index',
'Edges_X_Index', 'Edges_Y_Index', 'Outside_Global_Index', 'LogOfAreas',
'Log_X_Index', 'Log_Y_Index', 'Orientation_Index', 'Luminosity_Index',
'SigmoidOfAreas']]
y = df['K_Scatch']from sklearn.model_selection import train_test_split
from scipy.stats import zscore# sklearn.model_selection.train_test_split을 활용하여, x_train, x_test, y_train, y_test로 데이터를 나눕니다
# 그 비율은 8:2로 합니다. y값에 따라 stratify하여 나눕니다.
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=1, stratify=y)# pandas.DataFrame.apply를 활용하여 x_train과 x_test를 표준화합니다.
x_train = x_train.apply(zscore)
x_test = x_test.apply(zscore)x_train.describe()
로지스틱 분류 모형
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix
from sklearn import metrics# 로지스틱 회귀분석 모형을 만들어 lm에 저장합니다. solver는 'liblinear'로 설정합니다.
lm=LogisticRegression(solver='liblinear')https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
Grid Search 구축 ( Lidge, Lasso Penalty / Threshold )
# 로지스틱에서 고려해야할 Penalty의 형태 (Ridge, Lasso), regularization parameter range를 설정하여 이를 parameters에 dictionary 형태로 저장합니다. C값에 반비례하여 제한 값 정함, tol 값의 따르 수렴도 결정 linear
parameters={'penalty':['l1','l2'],'C':[0.01,0.1,0.5,0.9,1,5,10],'tol':[1e-6,1e-4,1e-2,1,1e2]}# sklearn.model_selection.GridSearchCV를 활용해 cv값 10, n_jobs값은 n_thread로, scoreing은 "accuracy"로 Grid Search를 세팅하고 이를 GSLR에 저장합니다.
GSLR=GridSearchCV(lm,parameters,cv=10,n_jobs=n_thread,scoring="accuracy")# (문제) Grid Search를 fit함수를 활용하여 수행합니다.
GSLR.fit(x_train,y_train)# 최적의 파라미터 값 및 정확도 (Accuracy) 출력
print('final params', GSLR.best_params_)
print('best score', GSLR.best_score_)
모형 평가 및 최적 로지스틱 모형 구축
# predict 함수를 활용하여 예측 값을 구해 이를 predicted 에 저장합니다.
predicted=GSLR.predict(x_test)predicted
# sklearn.metrics.confusion_matrix 활용하여 confusion_matrix를 구하고 이를 출력합니다.
cMatrix = confusion_matrix(y_test,predicted)
print(cMatrix)
print("\n Accuracy:", GSLR.score(x_test,y_test))
# sklearn.metrics.classification_report를 활용하여 report를 출력합니다.
print(metrics.classification_report(y_test,predicted))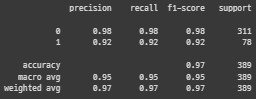
# Cross validation 과정에서 계산된 정확도 값들을 출력해줍니다.
means = GSLR.cv_results_['mean_test_score']
stds = GSLR.cv_results_['std_test_score']
for mean, std, params in zip(means, stds, GSLR.cv_results_['params']):
print("%0.3f (+/-%0.03f) for %r"
% (mean, std * 2, params))
print()
의사결정나무 모형
from sklearn.tree import DecisionTreeClassifier
# 의사결정나무 모형을 만들어 dt에 저장합니다.
dt=DecisionTreeClassifier()https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
Grid Search 구축 ( Loss function / Prunning )
# 의사결정나무에서 고려해야할 criterion, min_samples_split, max_depth, min_samples_leaf, max_features 등을 고려하여 Grid search를 수행합니다.
# GridSearchCV의 옵션은 cv=10, n_jobs=n_thread, scoreing="accuracy"로 설정합니다.
parameters={'criterion':['gini','entropy'],'min_samples_split':[2,5,10,15], 'max_depth':[None,2],'min_samples_leaf':[1,3,10,15],'max_features':[None,'sqrt','log2']}
GSDT=GridSearchCV(dt,parameters,cv=10,n_jobs=n_thread,scoring="accuracy")
GSDT.fit(x_train,y_train)print('final params',GSDT.best_params_)
print('ACC.',GSDT.best_score_)
모형 평가 및 최족 의사결정나무 구축
# predict 함수를 활용하여 예측 값을 구해 이를 predicted 에 저장하고 이를 출력하며 classification_report 또한 출력합니다.
predicted=GSDT.predict(x_test)
cMatrix = confusion_matrix(y_test,predicted)
print(cMatrix)
print(round(GSDT.score(x_test,y_test),3))
print(metrics.classification_report(y_test,predicted))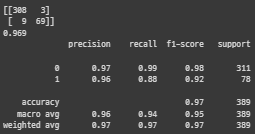
# Train에서의 종속변수의 분포
print(y_train.value_counts())
# 트리 시각화
import graphviz
from sklearn import tree
dt2=DecisionTreeClassifier(criterion='entropy',max_depth=None,max_features=None,min_samples_leaf=1,min_samples_split=5)
dt2.fit(x_train,y_train)
dot_data=tree.export_graphviz(dt2,feature_names=x_train.columns,filled=True,rounded=True)
graph=graphviz.Source(dot_data)
graph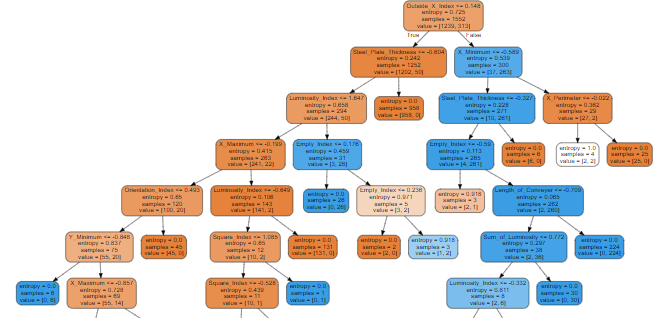
랜덤 포레스트

Random Forest 기본 모형 만들기
from sklearn.ensemble import RandomForestClassifier
# Random Forest 모형을 만들어 rf에 저장합니다.
rf=RandomForestClassifier()https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
Grid Search 구축 ( Loss function / Prunning / 변수 선택 / Tree 개수 )
# Random Forest에서 고려해야할 n_estimators, min_samples_split, max_depth, min_samples_leaf, max_features 등을 고려하여 Grid search를 수행합니다.
# GridSearchCV의 옵션은 cv=10, n_jobs=n_thread, scoreing="accuracy"로 설정합니다.
parameters={'n_estimators':[50,75,100,200],'criterion':['entropy'],'min_samples_split':[1,2,5],'max_depth':[None,2],'min_samples_leaf':[1,3,10],'max_features':['sqrt']}
GSRF=GridSearchCV(rf,parameters,cv=10,n_jobs=n_thread,scoring="accuracy")
GSRF.fit(x_train,y_train)
print('final params',GSRF.best_params_)
print('best score',GSRF.best_score_)
모형 평가 및 최적 Random Forest 구축
# predict 함수를 활용하여 예측 값을 구해 이를 predicted 에 저장하고 이를 출력하며 classification_report 또한 출력합니다.
predicted=GSRF.predict(x_test)
cMatrix=confusion_matrix(y_test,predicted)
print(cMatrix)
print(metrics.classification_report(y_test,predicted))
Support Vector Machine
from sklearn import svm
# Support Vector Machine을 만들어 svc에 저장합니다.
svc=svm.SVC()https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
Grid Search 구축 (Regularization / Kernel / Gamma )
# Support Vector Machine에서 고려해야할 C, kernel, gamma 등을 고려하여 Grid search를 수행합니다.
# GridSearchCV의 옵션은 cv=10, n_jobs=n_thread, scoreing="accuracy"로 설정합니다.
parameters={'C':[0.01,0.1,0.5,0.9,1,5,10],'kernel':['linear','rbf','poly'],'gamma':[0.05,0.1,1,10]}
GS_SVM=GridSearchCV(svc,parameters,cv=10,n_jobs=n_thread,scoring="accuracy")
GS_SVM.fit(x_train,y_train)
print('final params',GS_SVM.best_params_)
print('best score',GS_SVM.best_score_)
모델 평가 및 최적 Support Vector Machine 구축
# predict 함수를 활용하여 예측 값을 구해 이를 predicted 에 저장하고 이를 출력하며 classification_report 또한 출력합니다.
predicted=GS_SVM.predict(x_test)
cMatrix=confusion_matrix(y_test,predicted)
print(cMatrix)
print(metrics.classification_report(y_test,predicted))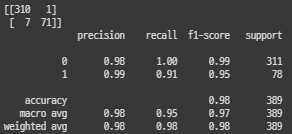
신경망 모형
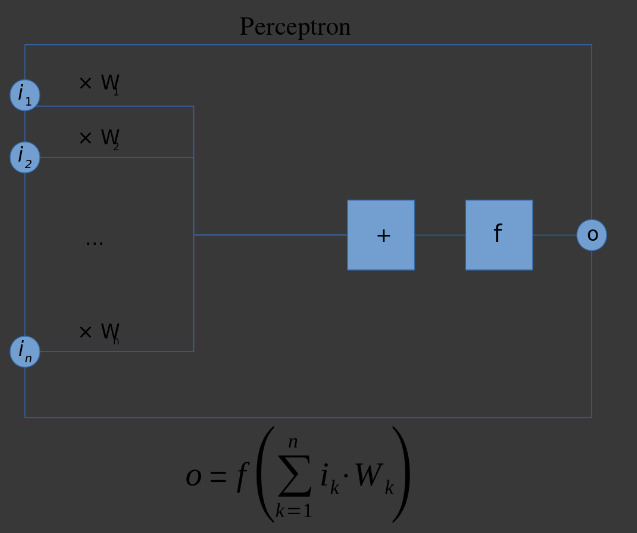
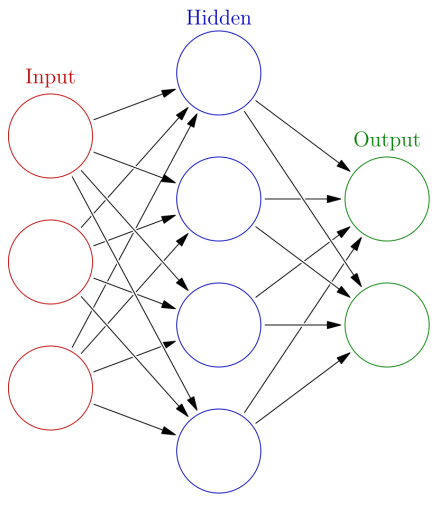
[ANN] 신경망 모형 기본 모형 만들기
from sklearn.neural_network import MLPClassifier
# 신경망 모형을 만들어 ann_model에 저장합니다.
nn_model=MLPClassifier(random_state=1)https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html
Grid Search 구축 ( Hidden Layer 수 / Hidden node 수 / Regularzation )
x_train.shape # (1552, 26)1552/(10*(26+1)) # 5.74814814814814851552/(1*(26+1)) # 57.48148148148148# 신경망 모형에서 고려해야할 alpha, hidden_layer_sizes, activation등을 고려하여 Grid search를 수행합니다.
# GridSearchCV의 옵션은 cv=10, n_jobs=n_thread, scoreing="accuracy"로 설정합니다.
parameters={'alpha':[1e-3,1e-1,1e1],'hidden_layer_sizes':[(5),(30),(60)],'activation':['tanh','relu'],'solver':['adam','lbfgs']}
GS_NN=GridSearchCV(nn_model,parameters,cv=10,n_jobs=n_thread,scoring="accuracy")
GS_NN.fit(x_train,y_train)print('final params', GS_NN.best_params_)
print('best score', GS_NN.best_score_)
means = GS_NN.cv_results_['mean_test_score']
stds = GS_NN.cv_results_['std_test_score']
for mean, std, params in zip(means, stds, GS_NN.cv_results_['params']):
print("%0.3f (+/-%0.03f) for %r"
% (mean, std * 2, params))
print()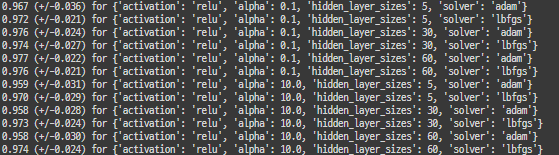
parameters2={'alpha':[1e-1],'hidden_layer_sizes':[(5),(10),(20),(30),(40)],'activation':['tanh'],'solver':['lbfgs']}
GS_NN2=GridSearchCV(nn_model,parameters2,cv=10,n_jobs=n_thread,scoring="accuracy")
GS_NN2.fit(x_train,y_train)print('final params', GS_NN.best_params_)
print('best score', GS_NN.best_score_)
parameters3={'alpha':[1e-1],'hidden_layer_sizes':[(30,2),(30,5)],'activation':['tanh'],'solver':['adam']}
GS_NN3=GridSearchCV(nn_model,parameters3,cv=10,n_jobs=n_thread,scoring="accuracy")
GS_NN3.fit(x_train,y_train)means = GS_NN2.cv_results_['mean_test_score']
stds = GS_NN2.cv_results_['std_test_score']
for mean, std, params in zip(means, stds, GS_NN2.cv_results_['params']):
print("%0.3f (+/-%0.03f) for %r"
% (mean, std * 2, params))
print()
모형 평가 및 최적 신경망 모형 구축
# predict 함수를 활용하여 예측 값을 구해 이를 predicted 에 저장하고 이를 출력하며 classification_report 또한 출력합니다.
predicted=GS_NN2.predict(x_test)
cMatrix=confusion_matrix(y_test,predicted)
print(cMatrix)
print(metrics.classification_report(y_test,predicted))
Boosting

xgboost 기본 모형 만들기
import xgboost as xgb
from sklearn.metrics import accuracy_score
# xgboost 모형을 만들어 xgb_model에 저장합니다. objective='binary:logistic'로 설정합니다.
xgb_model=xgb.XGBClassifier(objective='binary:logistic')https://xgboost.readthedocs.io/en/latest/parameter.html
xgboost Grid Search 구축 ( Max depth / Tree 개수 / Gamma )
# xgboost에서 고려해야할 max_depth, min_child_weight, gamma, colsample_bytree, n_estimators 등을 고려하여 Grid search를 수행합니다.
# GridSearchCV의 옵션은 cv=10, n_jobs=n_thread, scoreing="accuracy"로 설정합니다.
parameters={
'max_depth':[5,8],
'min_child_weight':[1,5], #이전 트리에서 child안 샘플이 몇개 있는지 결정. 이부분이 conservative하면 pruning을 미리 진행
'gamma':[0,1], #복잡도 영향 변수
'colsample_bytree':[0.8,1], #각가의 트리 구성시 parameter 탈락 비율 결정.
'colsample_bylevel':[0.9,1],# 구성된 각각의 노드의 parameter탈락 비율 결정
'n_estimators':[50,100]
}GS_xgb=GridSearchCV(xgb_model,param_grid=parameters,cv=10,n_jobs=n_thread,scoring="accuracy")
GS_xgb.fit(x_train,y_train)https://xgboost.readthedocs.io/en/latest/tutorials/param_tuning.html
print('final params',GS_xgb.best_params_)
print('best score',GS_xgb.best_score_)
parameters2={
'max_depth':[3,5,7],
'min_child_weight':[1],
'gamma':[0],
'colsample_bytree':[1],
'colsample_bylevel':[1],
'n_estimators':[150,200]
}
GS_xgb2=GridSearchCV(xgb_model,param_grid=parameters2,cv=10,n_jobs=n_thread,scoring="accuracy")
GS_xgb2.fit(x_train,y_train)print('final params',GS_xgb2.best_params_)
print('best score',GS_xgb2.best_score_)
모형 평가 및 최적 xgboost 모형 구축
# predict 함수를 활용하여 예측 값을 구해 이를 predicted 에 저장하고 이를 출력하며 classification_report 또한 출력합니다.
predicted=GS_xgb2.predict(x_test)
cMatrix=confusion_matrix(y_test,predicted)
print(cMatrix)
print(metrics.classification_report(y_test,predicted))
lightGBM 기본 모형 만들기
import lightgbm as lgb
# lightgbm 모형을 만들어 lgbm_model에 저장합니다. objective='binary' 로 설정합니다.
lgbm_model=lgb.LGBMClassifier(objecve='binary')https://lightgbm.readthedocs.io/en/latest/Parameters.html
lightGBM Grid Search 구축 ( Max depth / Tree 개수 )
# lightGBM에서 주로 고려해야할 num_leaves, min_data_in_leaf, colsample_bytree, n_estimators 등을 고려하여 Grid search를 수행합니다.
# GridSearchCV의 옵션은 cv=10, n_jobs=n_thread, scoreing="accuracy"로 설정합니다.
parameters={
'num_leaves':[32,64,128],
'min_data_in_leaf':[1,5,10],
'colsample_bytree':[0.8,1],
'n_estimators':[100,150]
}GS_lgbm=GridSearchCV(lgbm_model,parameters,cv=10,n_jobs=n_thread,scoring="accuracy")
GS_lgbm.fit(x_train,y_train)
print('final params',GS_lgbm.best_params_)
print('best score',GS_lgbm.best_score_)
모형 평가 및 최적 lightGBM 모형 구축
# predict 함수를 활용하여 예측 값을 구해 이를 predicted 에 저장하고 이를 출력하며 classification_report 또한 출력합니다.
predicted=GS_lgbm.predict(x_test)
cMatrix=confusion_matrix(y_test,predicted)
print(cMatrix)
print(metrics.classification_report(y_test,predicted))
결론
- 학습한 것:
- 기초 학습 내용은 각 모델들의 구축과정, 이 파라미터를 최적화 시키는 GridSearch에 대한 활용
- 심화 학습 내용은 위의 내용들을 데이터의 특성과 모델 방법론에 대한 개괄적 이해를 바탕으로 한 적정한 모델의 선택과 파라미터를 최적화 시키는 관점에서 바라보고 이해하는 것.
- 본 contents의 활용:
- 방법론의 최적 모형을 구축하면서 코멘트 드렸던 모형 별 중요 파라미터와 이 파라미터들이 가지는 의미, 파라미터들의 변화에 따른 예측력의 변화 경향성을 바탕으로 여러 데이터에서 데이터의 특성에 따른 모델의 성능과 최적 파라미터가 가지는 경향성을 경험적으로 습득후 여러 프로젝트에 응용
'빅데이터 분석가 양성과정 > Python - 딥러닝' 카테고리의 다른 글
| 공정 검사와 딥러닝 (0) | 2024.07.18 |
|---|---|
| 실습) Google Net (0) | 2024.07.18 |
| 이론 - DenseNet (1) | 2024.07.18 |
| 이론 - Residual Network (0) | 2024.07.18 |
| 이론 - 합성곱 신경망 ( Inception Network ) (1) | 2024.07.18 |