
https://finance.naver.com/marketindex/index.naver
환전 고시 환율 2024.07.09 10:11 하나은행 기준 고시회차 91회
finance.naver.com
환율 가져오기
import urllib.request as request
from bs4 import BeautifulSoup
url = '<https://finance.naver.com/marketindex/index.naver>'
html = request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
ul_tag = soup.find(id = "exchangeList")
li_tag = ul_tag.find('li', {'class':'on'})
a_tag = li_tag.find('a')
div_tag = a_tag.find('div', {'class':'head_info point_dn'})
span_tag = div_tag.find('span')
span_tag.text
1,275.50
import urllib.request as request
from bs4 import BeautifulSoup
url = '<https://finance.naver.com/marketindex/index.naver>'
html = request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
ul_tag = soup.find(id = "exchangeList")
sp_tag = li_tag.find('span', {'class':'value'})
sp_tag.text
1,275.50
span2_tag = div_tag.find('span', {'class','txt_krw'})
span3_tag = span2_tag.find('span', {'class','blind'})
span3_tag.text
원
select 요소 사용
import urllib.request as request
from bs4 import BeautifulSoup
url = '<https://finance.naver.com/marketindex/index.naver>'
html = request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
mon = soup.select_one('ul#exchangeList > li.on > a.head.usd > div.head_info.point_dn > span.value ').text
print(mon)
1,274.10
시
import urllib.request as request
from bs4 import BeautifulSoup
url = '<https://ko.wikisource.org/wiki/%ED%95%98%EB%8A%98%EA%B3%BC_%EB%B0%94%EB%9E%8C%EA%B3%BC_%EB%B3%84%EA%B3%BC_%EC%8B%9C>'
html = request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
li_tags = soup.select('div#mw-content-text > div.mw-parser-output > ul > li')
title = []
link = []
for li_tag in li_tags:
title.append(li_tag.text)
link.append(li_tag.find('a').get('href'))
base_url = '<https://ko.wikisource.org>'
poem = []
for idx in range(len(link)):
url = base_url + link[idx]
html = request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
print('[' + title[idx] + ']')
try:
p_tag = soup.select_one('div#mw-content-text > div.mw-parser-output > div.poem > p')
print(p_tag.text)
except:
p_tag = soup.select_one('div#mw-content-text > div.mw-parser-output > p')
print(p_tag.text)
print('-'*32)
어머님, 나는 별 하나에 아름다운 말 한 마디씩 불러 봅니다.
소학교 때 책상을 같이했던 아이들의 이름과, 패, 경, 옥 이런 이국 소녀들의 이름과, 벌써 아기 어머니 된 계집애들의 이름과, 가난한 이웃 사람들의 이름과, 비둘기, 강아지, 토끼, 노새, 노루, '프랑시스 잠', '라이너 마리아 릴케', 이런 시인의 이름을 불러 봅니다.
이네들은 너무나 멀리 있습니다. 별이 아스라이 멀 듯이,
어머님, 그리고 당신은 멀리 북간도에 계십니다
나는 무엇인지 그리워 이 많은 별빛이 내린 언덕 위에 내 이름자를 써 보고, 흙으로 덮어 버리었읍니다.
딴은, 밤을 새워 우는 벌레는 부끄러운 이름을 슬퍼하는 까닭입니다.
그러나 겨울이 지나고 나의 별에도 봄이 오면 무덤 위에 파란 잔디가 피어나듯이 내 이름자 묻힌 언덕 위에도 자랑처럼 풀이 무성할 게외다.
------------------------------—
네이버 오픈 API
종류


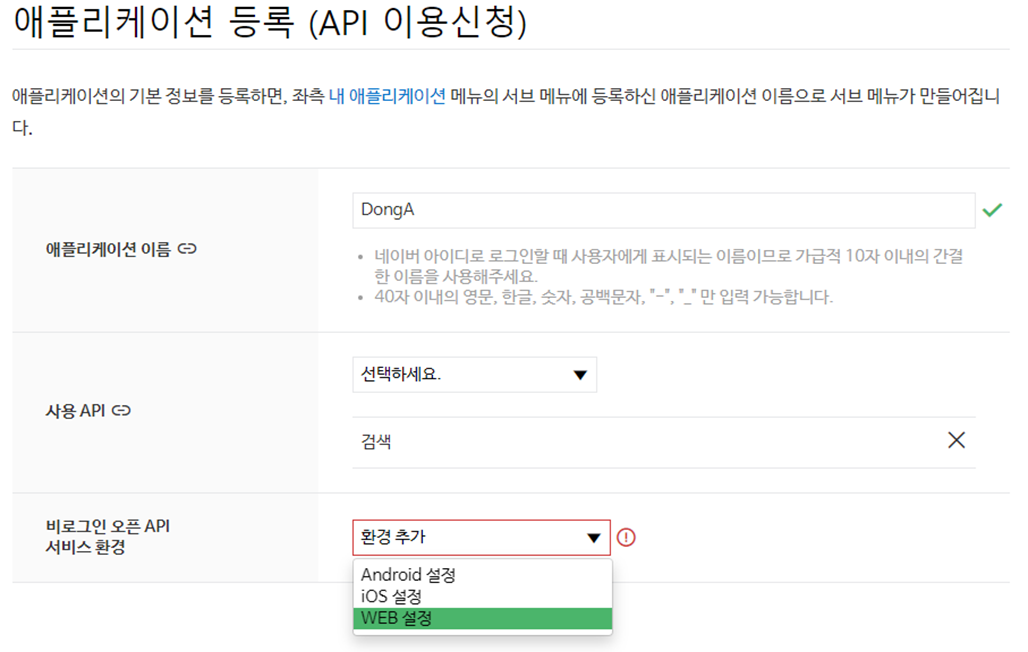

블로그 검색
오픈 API 등록하고 아이디 비번 기록
import requests
client_id = 'Ly6eZQMqPw9xvXbOCMwm'
client_secret = 'ma7qpBCpDf'
headers = {'X-Naver-Client-Id':client_id, 'X-Naver-Client-Secret':client_secret}
- 블로그, 뉴스, 등 각각 사용방법 다름
- blog는 query = ‘검색하고 싶은 키워드’
url = '<https://openapi.naver.com/v1/search/blog?query=강남역>'
result = requests.get(url, headers=headers)
result.json() # json 은 딕셔너리와 유사
{'lastBuildDate': 'Thu, 27 Jul 2023 15:31:41 +0900',
'total': 2106289,
'start': 1,
'display': 10,
'items': [{'title': '수준급의 <b>강남역</b> 고기집',
'link': 'https://blog.naver.com/kikihyeji/223162725701',
'description': '강남구 강남대로98길 12 1층 전화번호 : 0507-1345-1806 영업시간 : 매일 12:00 - 23:00 유니네 고깃간은 <b>강남역</b> 11번출구에서 걸어서 5분정도 걸리는 곳에 위치해있어요. 더운 날 오래 걷지않아도 되는 역 근처에... ',
'bloggername': '최주부의 일상',
'bloggerlink': 'blog.naver.com/kikihyeji',
'postdate': '20230721'},
dic = result.json()
dic.keys()
dict_keys(['lastBuildDate', 'total', 'start', 'display', 'items'])
- display 기본값 : 10 , start 기본값 : 1
url = '<https://openapi.naver.com/v1/search/blog?query=강남역&display=20&start=1&sort=sim>' result = requests.get(url, headers=headers) information = result.json() information
{'lastBuildDate': 'Thu, 27 Jul 2023 15:31:41 +0900',
'total': 2106289,
'start': 1,
'display': 10,
'items': [{'title': '수준급의 <b>강남역</b> 고기집',
'link': 'https://blog.naver.com/kikihyeji/223162725701',
'description': '강남구 강남대로98길 12 1층 전화번호 : 0507-1345-1806 영업시간 : 매일 12:00 - 23:00 유니네 고깃간은 <b>강남역</b> 11번출구에서 걸어서 5분정도 걸리는 곳에 위치해있어요. 더운 날 오래 걷지않아도 되는 역 근처에... ',
'bloggername': '최주부의 일상',
'bloggerlink': 'blog.naver.com/kikihyeji',
'postdate': '20230721'},
print('검색 일 :',information['lastBuildDate'])
print('총 검색 결과 :', information['total'])
print('시작 위치 :', information['start'])
print('출력 개수 :', information['display'])
검색 일 : Thu, 27 Jul 2023 15:37:08 +0900 총 검색 결과 : 2106297 시작 위치 : 1 출력 개수 : 20
- items = 딕셔너리 요소 가진 리스트 형태
print('items :', information['items'])
print(len(information['items']))

information['items'][0]

뉴스 검색
- news.json?query = 검색어
url = '<https://openapi.naver.com/v1/search/news.json?query=강남역&sort=sim>'
result = requests.get(url, headers=headers)
result.json()
{'lastBuildDate': 'Thu, 27 Jul 2023 16:15:27 +0900', 'total': 206955, 'start': 1, 'display': 10, 'items': [{'title': '퇴근길 <b>강남역</b> ‘압사 위험’ 신고…한때 진입 통제', 'originallink': 'http://www.edaily.co.kr/news/newspath.asp?newsid=02755206635676816', 'link': 'https://n.news.naver.com/mnews/article/018/0005535367?sid=102', 'description': '21일 퇴근 시간대 서울지하철 <b>강남역</b>에서 압사 사고가 우려된다는 신고로 경찰이 출동하고 일부 출구 진입이 통제되는 소동이 벌어졌다. 서울 강남구 지하철 2호선 <b>강남역</b> 승강장에 역명판이 설치돼 있다. (사진=뉴시스)... ', 'pubDate': 'Fri, 21 Jul 2023 20:38:00 +0900'},
- display 최댓값은 100 인데 1000개 기사 가져오기
base_url = '<https://openapi.naver.com/v1/search/news.json?query=빅데이터&display=100>'
data = []
for idx in range(10):
url = base_url+'start={}&sort=sim'.format(idx*100 + 1)
information = requests.get(url, headers = headers).json()
items = information['items']
for item in items:
title = item['title']
link = item['link']
data.append([title, link])
print(len(data))
1000
data

'빅데이터 분석가 양성과정 > Python' 카테고리의 다른 글
| Numpy ( 2 ) (0) | 2024.07.09 |
|---|---|
| Numpy ( 1 ) (0) | 2024.07.09 |
| Web Crawling - 옷 쇼핑몰 (0) | 2024.07.09 |
| Web Crawling - find() (0) | 2024.07.09 |
| Web Crawling - 기초 (0) | 2024.07.09 |