데이터 확인
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('churn.csv')
data

# 출력하는 열 개수 지정
pd.set_option('display.max_columns', 30)
# 출력하는 행 개수 지정
pd.set_option('display.max_rows', 100)
data.info()

# 공백 문자열을 NaN으로 변경하기
data['TotalCharges'] = data['TotalCharges'].replace(" ", np.nan)
# or
# data['TotalCharges'] = data['TotalCharges'].replace(" ", "")
# 숫자로 변환 (숫자로 변환할 수 없는 값을 NaN으로 변경)
data['TotalCharges'] = pd.to_numeric(data['TotalCharges'], errors='coerce')
# data['TotalCharges'] = pd.to_numeric(data['TotalCharges'])
pd.to_numeric(data['TotalCharges'])

# 데이터 요약 정보
data.describe()

sns.distplot(data['TotalCharges'])

카테고리 변수 처리
# 오브젝트인지 확인
data['gender'].dtype == 'O' # True
col_list=[]
for i in data.columns:
if data[i].dtype == 'O':
col_list.append(i)
col_list

for i in col_list:
print(i, data[i].nunique())

# 열 이름
col_list = col_list[1:]
col_list

# 열 이름 새로 지정
data = pd.get_dummies(data, columns=col_list, drop_first = True)
data

결측값 처리
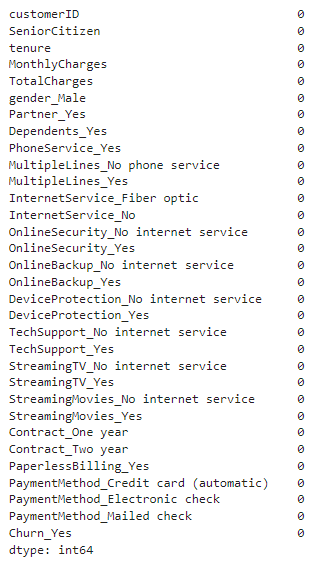
data.isna().sum()

# 결측값을 중앙값으로 대체
data['TotalCharges'] = data['TotalCharges'].fillna(data['TotalCharges'].median())
data.isna().sum()
데이터 스케일링

# 표준 스케일러
standard = StandardScaler()
standard.fit(data.drop('Churn_Yes', axis=1))
scaled_st = standard.transform(data.drop('Churn_Yes', axis=1))
scaled_st2=pd.DataFrame(scaled_st, columns = data.drop('Churn_Yes', axis=1).columns)
scaled_st2

# Robust 스케일러
rob = RobustScaler()
rob.fit(data.drop('Churn_Yes', axis=1))
scaled_rob = rob.transform(data.drop('Churn_Yes', axis=1))
pd.DataFrame(scaled_rob, columns = data.drop('Churn_Yes', axis=1).columns)

# Min-Max 스케일러 저장
scaled_data = pd.DataFrame(scaled_data, columns= data.columns)
scaled_data

Train / Test 와 모델링
from sklearn.model_selection import train_test_split
X = scaled_data.drop('Churn_Yes', axis = 1)
y = scaled_data['Churn_Yes']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state =100)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train, y_train)
pred = knn.predict(X_test)
pd.DataFrame({'acutal_value': y_test, 'pred_value' : pred }).head(30)
from sklearn.metrics import accuracy_score, confusion_matrix
accuracy_score(y_test, pred) # 모델의 정확도 : 0.7581637482252721
confusion_matrix(y_test, pred)

최적의 K값 찾기
error_list = []
for i in range(1,101):
knn = KNeighborsClassifier(n_neighbors = i)
knn.fit(X_train, y_train)
pred = knn.predict(X_test)
error_list.append(accuracy_score(y_test, pred))
plt.figure(figsize=(20,10))
sns.lineplot(x = range(1,101), y = error_list, marker = 'o', markersize=10, markerfacecolor='red')
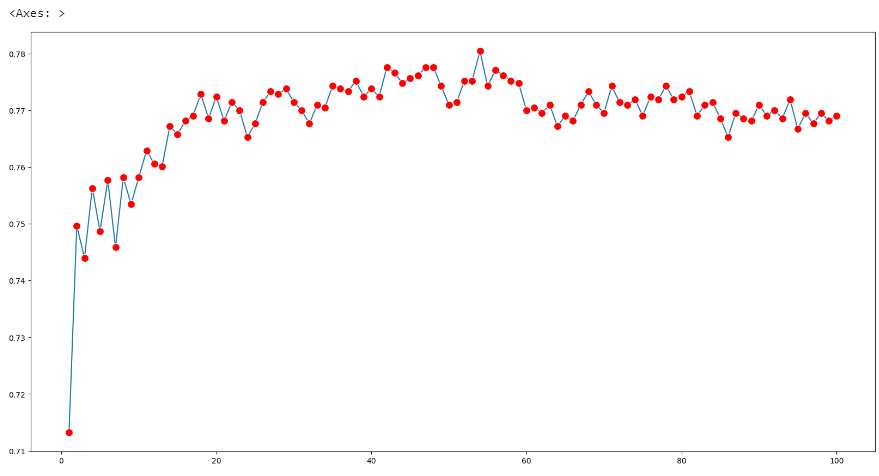
max(error_list) # 0.780407004259347
error_list.index(max(error_list)) # 53
np.array(error_list).argmax() # 53
error_list[0] # 0.7132039753904401
knn = KNeighborsClassifier(n_neighbors = 54)
knn.fit(X_train, y_train)
pred = knn.predict(X_test)
accuracy_score(y_test, pred) # 0.780407004259347
confusion_matrix(y_test,pred)

