
아이오와주 에임스 지역 집값 예측
데이터 불러오기 및 확인
import pandas as pd
# 깃허브에 데이터를 가져옴
!git clone https://github.com/taehojo/data.git
# 집 값 데이터를 불러옴
df = pd.read_csv("./data/house_train.csv")
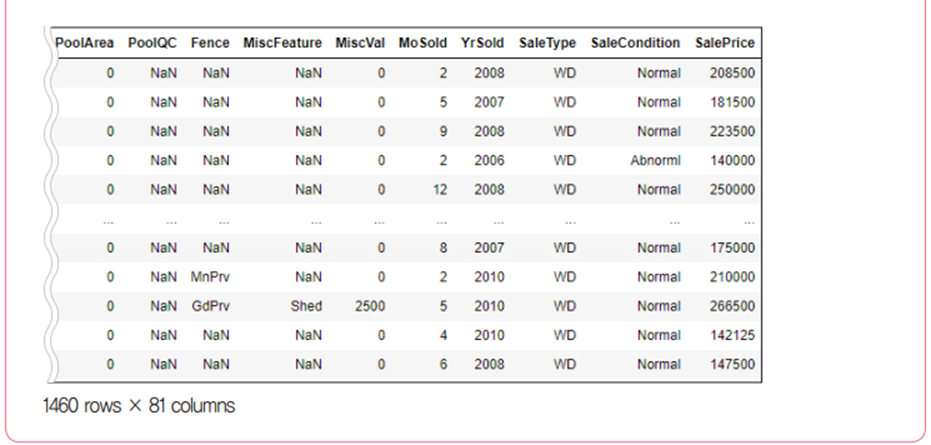
# 데이터 파악하기
df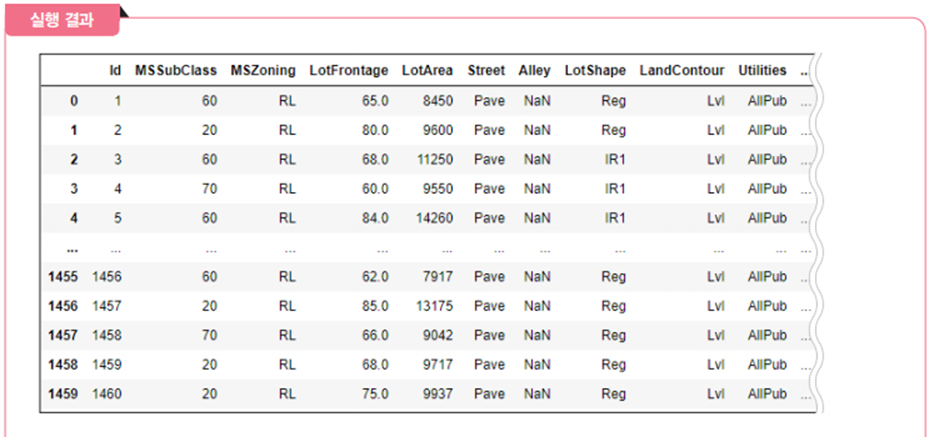
카테고리 변수 처리
df['SaleCondition'].value_counts()
# 카테고리형 변수를 0과 1로 이루어진 변수로 변경
df = pd.get_dummies(df)
SaleCondition_cols = [col for col in df.columns if 'SaleCondition' in col]
SaleCondition_cols
df[SaleCondition_cols]

결측치 처리
# 결측치를 전체 칼럼의 평균으로 대체하여 채움
df = df.fillna(df.mean())
# 속성별로 결측치가 몇 개인지 확인
df.isnull().sum().sort_values(ascending=False).head(20)
속성별 관련도 추출
# 데이터 사이의 상관 관계를 저장
df_corr = df.corr()
# 집 값과 관련이 큰 것부터 순서대로 저장
df_corr_sort = df_corr.sort_values('SalePrice', ascending=False)
# 집 값과 관련도가 가장 큰 10개의 속성들을 출력df_corr_sort['SalePrice'].head(10)
# 집 값과 관련도가 가장 높은 속성들(여기서는 5개)을 추출해서 상관도 그래프
cols=['SalePrice','OverallQual','GrLivArea','GarageCars','GarageArea','TotalBsmtSF']
sns.pairplot(df[cols])
plt.show();
cols = ['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars', 'GarageArea', 'TotalBsmtSF']
sns.pairplot(df[cols])
plt.show()
# 중요 속성만 추려서 학습 데이터 셋을 만듬
cols_train=['OverallQual','GrLivArea','GarageCars','GarageArea','TotalBsmtSF']
X_train_pre = df[cols_train]
# 집 값을 저장
y = df['SalePrice'].values
데이터 셋 분할
# 학습 데이터, 테스트 데이터 준비
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
모델 구성
model = Sequential()
model.add(Dense(10, input_dim=X_train.shape[1], activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(40, activation='relu'))
model.add(Dense(1))model.compile(optimizer ='adam', loss = 'mean_squared_error')
과적합 방지
# 20회 이상 결과가 향상되지 않으면 자동으로 중단되게끔 설정
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
# 모델의 이름
modelpath="./data/model/Ch15-house.hdf5"
# 모델을 업데이트하고 저장
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss',
verbose=0, save_best_only=True)history = model.fit(X_train, y_train,
validation_split=0.25,
epochs=2000,
batch_size=32,
callbacks=[early_stopping_callback, checkpointer])
성능 시각화
y_pre = model.predict(X_test).flatten()
y = y_test
plt.figure(figsize=(24, 9))
plt.plot(y, 'b', label='real price')
plt.plot(y_pre, 'r', label='predicted price')
plt.legend()
plt.grid()
plt.show()
# 예측 값과 실제 값, 실행 번호가 들어갈 빈 리스트를 생성
real_prices =[]
pred_prices = []
X_num = []
# 25개의 샘플을 뽑아 실제 값, 예측 값을 출력해 봅니다.
n_iter = 0
Y_prediction = model.predict(X_test).flatten()
for i in range(25):
real = y_test[i]
prediction = Y_prediction[i]
print("실제가격: {:.2f}, 예상가격: {:.2f}".format(real, prediction))
real_prices.append(real)
pred_prices.append(prediction)
n_iter = n_iter + 1
X_num.append(n_iter)
plt.plot(X_num, pred_prices, label='predicted price')
plt.plot(X_num, real_prices, label='real price')
plt.legend()
plt.show()

'빅데이터 분석가 양성과정 > Python - 딥러닝' 카테고리의 다른 글
| 딥러닝을 이용한 자연어 처리 (1) | 2024.07.17 |
|---|---|
| 이미지 인식 - CNN (0) | 2024.07.17 |
| 모델 성능 향상 (1) | 2024.07.17 |
| 모델 성능 검증 (0) | 2024.07.17 |
| 다중 분류 - iris 데이터 (0) | 2024.07.17 |
아이오와주 에임스 지역 집값 예측
데이터 불러오기 및 확인
python
import pandas as pd
# 깃허브에 데이터를 가져옴
!git clone https://github.com/taehojo/data.git
# 집 값 데이터를 불러옴
df = pd.read_csv("./data/house_train.csv")
# 데이터 파악하기
df
카테고리 변수 처리
python
df['SaleCondition'].value_counts()
python
# 카테고리형 변수를 0과 1로 이루어진 변수로 변경
df = pd.get_dummies(df)
SaleCondition_cols = [col for col in df.columns if 'SaleCondition' in col]
SaleCondition_cols
df[SaleCondition_cols]
결측치 처리
python
# 결측치를 전체 칼럼의 평균으로 대체하여 채움
df = df.fillna(df.mean())
# 속성별로 결측치가 몇 개인지 확인
df.isnull().sum().sort_values(ascending=False).head(20)
속성별 관련도 추출
python
# 데이터 사이의 상관 관계를 저장
df_corr = df.corr()
# 집 값과 관련이 큰 것부터 순서대로 저장
df_corr_sort = df_corr.sort_values('SalePrice', ascending=False)
# 집 값과 관련도가 가장 큰 10개의 속성들을 출력df_corr_sort['SalePrice'].head(10)
python
# 집 값과 관련도가 가장 높은 속성들(여기서는 5개)을 추출해서 상관도 그래프
cols=['SalePrice','OverallQual','GrLivArea','GarageCars','GarageArea','TotalBsmtSF']
sns.pairplot(df[cols])
plt.show();
python
cols = ['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars', 'GarageArea', 'TotalBsmtSF']
sns.pairplot(df[cols])
plt.show()
python
# 중요 속성만 추려서 학습 데이터 셋을 만듬
cols_train=['OverallQual','GrLivArea','GarageCars','GarageArea','TotalBsmtSF']
X_train_pre = df[cols_train]
# 집 값을 저장
y = df['SalePrice'].values
데이터 셋 분할
python
# 학습 데이터, 테스트 데이터 준비
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
모델 구성
python
model = Sequential()
model.add(Dense(10, input_dim=X_train.shape[1], activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(40, activation='relu'))
model.add(Dense(1))
python
model.compile(optimizer ='adam', loss = 'mean_squared_error')
과적합 방지
python
# 20회 이상 결과가 향상되지 않으면 자동으로 중단되게끔 설정
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
# 모델의 이름
modelpath="./data/model/Ch15-house.hdf5"
# 모델을 업데이트하고 저장
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss',
verbose=0, save_best_only=True)
python
history = model.fit(X_train, y_train,
validation_split=0.25,
epochs=2000,
batch_size=32,
callbacks=[early_stopping_callback, checkpointer])
성능 시각화
python
y_pre = model.predict(X_test).flatten()
y = y_test
plt.figure(figsize=(24, 9))
plt.plot(y, 'b', label='real price')
plt.plot(y_pre, 'r', label='predicted price')
plt.legend()
plt.grid()
plt.show()
python
# 예측 값과 실제 값, 실행 번호가 들어갈 빈 리스트를 생성
real_prices =[]
pred_prices = []
X_num = []
# 25개의 샘플을 뽑아 실제 값, 예측 값을 출력해 봅니다.
n_iter = 0
Y_prediction = model.predict(X_test).flatten()
for i in range(25):
real = y_test[i]
prediction = Y_prediction[i]
print("실제가격: {:.2f}, 예상가격: {:.2f}".format(real, prediction))
real_prices.append(real)
pred_prices.append(prediction)
n_iter = n_iter + 1
X_num.append(n_iter)
plt.plot(X_num, pred_prices, label='predicted price')
plt.plot(X_num, real_prices, label='real price')
plt.legend()
plt.show()
'빅데이터 분석가 양성과정 > Python - 딥러닝' 카테고리의 다른 글
| 딥러닝을 이용한 자연어 처리 (1) | 2024.07.17 |
|---|---|
| 이미지 인식 - CNN (0) | 2024.07.17 |
| 모델 성능 향상 (1) | 2024.07.17 |
| 모델 성능 검증 (0) | 2024.07.17 |
| 다중 분류 - iris 데이터 (0) | 2024.07.17 |