
RNN
순환 신경망(RNN, Recurrent Neural Network)
- 연속된 데이터가 순서대로 입력되었을 때 앞서 입력받은 데이터를 잠시 기억해 놓는 방법
- 기억된 데이터 당 중요도 가중치를 주면서 다음 데이터로 넘어감
- 모든 입력 값에 이 작업을 순서대로 실행. 다음 층으로 넘어가기 전 같은 층을 맴도는 것처럼 보임


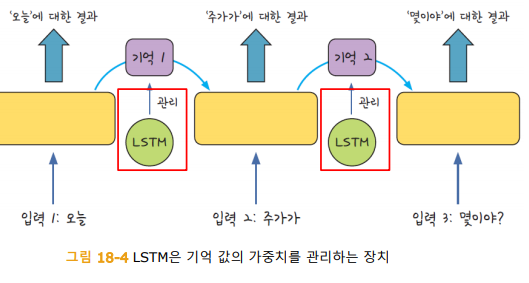
LSTM
LSTM(Long Short Term Memory)
- RNN의 기울기 소실 문제 보완을 위해 나온 방법
- 한 층에서 반복되기 직전에 다음 층으로 기억된 값을 넘길지 관리하는 단계를 하나 더 추가하는 것


# 로이터 뉴스 데이터셋 불러오기
from tensorflow.keras.datasets import reuters# 불러온 데이터를 Test/Train으로 분할
(X_train, Y_train),(X_test, Y_test) = reuters.load_data(num_words=None, test_split=0.2)category = numpy.max(Y_train + 1)
print( category, '카테고리' )
print( len(X_train), '학습용 뉴스 기사' ) #8982
print( len(X_test), '테스트용 뉴스 기사 ) #2246
print(X_train[0]) # [1, 2, 2, 8, 43, 10, 477...]from keras.preprocessing import sequence
# 학습 데이터 셋의 각 샘플의 요소의 개수가 같도록 맞춤 - 데이터 전처리
X_train = sequence.pad_sequences(X_train, maxlen=100)
X_test = sequence.pad_sequences(X_test, maxlen=100)
y_train = np_utils.to_categorical(Y_train)
y_test = np_utils.to_categorical(Y_test)# 모델 구조 설정
model = Sequential()
model.add(Embedding(1000,100))
model.add(LSTM(100, activation='tanh'))
model.add(Dense(46, activation='softmax'))Embedding
- 데이터 전처리 과정을 통해 입력된 값을 받아 다음 층이 알아들을 수 있는 형태로 변환하는 역할을 함
- Embedding('불러온 단어의 총 개수', '기사당 단어 수') 형식으로 사용하며, 모델 설정 부분의 맨 처음에 있어야
LSTM
- RNN에서 기억 값에 대한 가중치를 제어하며, LSTM(기사당 단어 수, 기타 옵션)의 형식으로 적용됨
- LSTM의 활성화 함수로는 tanh를 사용함
# 모델의 실행 옵션을 정합니다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델을 실행합니다.
history = model.fit(X_train, y_train, batch_size=20, epochs=20, validation_data=(X_test, y_test))
#정확도 출력
print('\n Test Accuracy: %.4f' % (model.evaluate(X_test, Y_test)[1]))
양방향 LSTM
- LSTM(Long Short Term Memory) ,RNN은 시계열 데이터 처리에 특화되어 은닉층에서 과거의 정보를 기억
- 순환 신경만의 특성상 입력 순으로 처리되므로 이전시점의 정보만 활용
- 문장이 길어지면 성능이 저화 될수 밖에 없음

- 정방향, 역방향 LSTM 계층에 모든 출력값을 연결해야 하므로 return_sequence 인자를 반드시 True
- Dense 계층을 TimeDistributred 래퍼를 사용해 3차원 텐서를 입력받아야 한다.

개체명 인식(Named Entity Recognition)이란 ?
문장내 포함된 어떤단어가 인물, 장소, 날짜등을 의미하는 단어인지 인식

BIO 표기법 (Beginning, Inside, Outside)
- B-개체명이 시작되는 단어 B-개체명, I는 B-개체명과 연결되는 단어일때 I-개체명, O는 개체명 이외의 모든 토큰

from tensorflow.keras.models import Sequential
from tensorflow.keras. layers import LSTM, Embedding, Dense, TimeDistributed, Dropout, Bidirectional
from tensorflow.keras.optimizers import Adam
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=30, input_length=max_len, mask_zero=True))
model.add(Bidirectional (LSTM(200, return_sequences=True, dropout=0.50, recurrent_dropout=0.25)))
model.add(TimeDistributed (Dense(tag_size, activation='softmax')))
model.compile(loss=' categorical_crossentropy', optimizer Adam (0.01), metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=128, epochs=10)
print(":", model.evaluate(x_test, y_test)[1])

Attention 신경망

- 그림 은 인코더에 입력된 각 셀 값을 하나씩 뒤로 보내다가, 맨 마지막 셀이 이 값을 디코더에 전달하는 것을 보여 줌
- 이 마지막 셀에 담긴 값에 전체 문장의 뜻이 함축되어 있으므로 이를 문맥 벡터(context vector)라고 함

- 마지막 셀에 모든 입력이 집중되던 RNN의 단점을 훌륭히 극복해 낸 알고리즘
from tensorflow. keras.models import Sequential
from tensorflow.keras. layers import Dense, Dropout, Activation, Embedding, LSTM, Conv1D, MaxPooling1D
from tensorflow.keras.datasets import imdb
from tensorflow. keras.preprocessing import sequence
from tensorflow.keras.callbacks import EarlyStopping
from attention import Attention
import numpy as np
import matplotlib.pyplot as plt
#데이터를 불러와 학습셋, 테스트셋으로 나눕니다.
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=5000)
# 단어의 수를 맞춥니다.
X_train = sequence.pad_sequences (X_train, maxlen=500)
X_test = sequence. pad_sequences (X_test, maxlen=500)
#모델의 구조를 설정합니다.
model Sequential()
model.add(Embedding (5000, 500))
model.add(Dropout (0.5))
model.add(LSTM (64, return_sequences=True))
model.add(Attention())
model.add(Dropout (0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
# 모델의 실행 옵션을 정합니다.
model.compile(loss='binary_crossentropy', optimizer='adam',
metrics=['accuracy'])
#학습의 조기 중단을 설정합니다.
early_stopping_callback = EarlyStopping (monitor= 'val_loss', patience=3)
#모델을 실행합니다.
history = model.fit(X_train, y_train, batch_size=40, epochs=100,
validation_data=(X_test, y_test), callbacks=[early_stopping_callback])
#테스트 정확도를 출력합니다.
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test) [1]))
#학습셋과 테스트셋의 오차를 저장합니다.
y_vloss = history.history['val_loss']
y_loss = history.history['loss']'
#그래프로 표현해 보겠습니다.
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
#그래프에 그리드를 주고 레이블을 표시하겠습니다.
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()



'빅데이터 분석가 양성과정 > Python - 딥러닝' 카테고리의 다른 글
| 오토인코더 (0) | 2024.07.18 |
|---|---|
| 비지도학습 신경망(GAN) (1) | 2024.07.18 |
| 자연어 처리_재정리 (2) | 2024.07.18 |
| DNN을 이용한 영상 분류_재정리 (0) | 2024.07.18 |
| 딥러닝 사전지식 ( Pre-knowledge ) (1) | 2024.07.17 |