

최종 추천모델 클래스 구성
- Matrix Factorization(SVD), Machine Learning(GBR), Content+Poupularity 추천을 생성하는 코드
SVD Recommender
import pandas as pd
from surprise import Dataset, Reader
from surprise import SVD
from sklearn.ensemble import GradientBoostingRegressor
class SVDRecommender:
def __init__(self, df_mf):
self.df_mf = df_mf
self.svd_model = self.fit_svd_model()
def fit_svd_model(self):
# Preprocessing
df_mf = self.df_mf[['user_id', 'isbn', 'rating']].drop_duplicates()
user_list = df_mf.groupby("user_id").size().reset_index(name='review_cnt')
user_list = user_list[user_list['review_cnt'] >= 30]
df_mf = df_mf[df_mf['user_id'].isin(user_list['user_id'])]
# Ensure reader is defined
reader = Reader(rating_scale=(1, 5)) # Adjust scale as needed
# Train
train_data = Dataset.load_from_df(df_mf[['user_id', 'isbn', 'rating']], reader)
trainset = train_data.build_full_trainset()
svd = SVD()
svd.fit(trainset)
return svdGBR Recommender
class GBRRecommender:
def __init__(self, ml_train_set, book_info, user_info):
self.ml_train_set = ml_train_set
self.book_info = book_info
self.user_info = user_info
self.gbr_model = self.fit_gbr_model()
def fit_gbr_model(self):
# Prepare data for GBR fitting
df_mf = self.preprocessing(self.ml_train_set)
# Train
X_train, y_train = self.split_data(df_mf)
gbr_model = GradientBoostingRegressor(random_state=42)
gbr_model.fit(X_train, y_train)
return gbr_model
def preprocessing(self, df):
df_mf = df[['user_id', 'isbn', 'rating']].drop_duplicates()
user_list = df_mf.groupby("user_id").size().reset_index(name='review_cnt')
user_list = user_list[user_list['review_cnt'] >= 30]
df_mf = df_mf[df_mf['user_id'].isin(user_list['user_id'])]
merged_df = df_mf.merge(self.book_info, on='isbn')\
.merge(self.user_info[['user_id', 'age']].drop_duplicates(), on='user_id')
return self.encode_categorical_columns(merged_df)
def encode_categorical_columns(self, df):
"""Encode categorical columns in the DataFrame."""
categorical_columns = ['isbn', 'book_author', 'category']
for column in categorical_columns:
df[f'{column}_encoded'] = df[column].astype('category').cat.codes
return df
def split_data(self, df):
features = ['age', 'isbn_encoded', 'book_author_encoded', 'year_of_publication',
'rating_mean', 'rating_count', 'category_encoded']
# Check if all features exist in the DataFrame
missing_features = [feature for feature in features if feature not in df.columns]
if missing_features:
print(f"Missing features: {missing_features}")
raise KeyError(f"None of {missing_features} are in the input DataFrame")
X = df[features]
y = df['rating']
return X, yFinal Book Recommender with SVD, GBR, Content&Popularity
- SVD Recommender와 GBR Recommender 클래스를 상속받아 Book Recommender 에서는 3개의 알고리즘을 이용해 추천셋 생성
class BookRecommender(SVDRecommender, GBRRecommender):
def __init__(self, df_mf, book_info, book_rec, ml_train_set, cosine_sim):
SVDRecommender.__init__(self, df_mf)
GBRRecommender.__init__(self, ml_train_set, book_info, ml_train_set[['user_id', 'age']].drop_duplicates())
self.book_info = book_info
self.book_rec = book_rec
self.cosine_sim = cosine_sim
def get_recommended_items_mf(self, user_id, top_n):
"""Matrix Factorization based recommendations"""
user_reviewed_iid = self.df_mf[self.df_mf['user_id'] == user_id]['isbn']
iid_to_est = self.df_mf[~self.df_mf['isbn'].isin(user_reviewed_iid)]['isbn'].drop_duplicates()
testset = [(user_id, iid, None) for iid in iid_to_est]
predictions = self.svd_model.test(testset)
predictions = pd.DataFrame(predictions)[['uid', 'iid', 'est']]
predictions.columns = ['user_id', 'isbn', 'predicted_rating']
predictions['predicted_rank'] = predictions['predicted_rating'].rank(method='first', ascending=False)
predictions = predictions.sort_values("predicted_rank")[:top_n]
predictions = predictions.merge(self.book_info, on='isbn')
return predictions[['user_id', 'isbn', 'book_title', 'book_author']]
def get_recommended_items_ml(self, user_id, top_n):
"""Machine Learning (GBR) based recommendations"""
user_reviewed_iid = self.df_mf[self.df_mf['user_id'] == user_id]['isbn']
iid_to_est = self.df_mf[~self.df_mf['isbn'].isin(user_reviewed_iid)]['isbn'].drop_duplicates()
ml_test_set = self.ml_train_set[self.ml_train_set['isbn'].isin(iid_to_est)]
user_age = self.ml_train_set[self.ml_train_set['user_id'] == user_id]['age'].unique()
features = ['age', 'isbn_encoded', 'book_author_encoded', 'year_of_publication',
'rating_mean', 'rating_count', 'category_encoded']
X = ml_test_set[features].query("age == @user_age")
y_pred = self.gbr_model.predict(X)
gbr_rec_result = X.copy()
gbr_rec_result['y_pred'] = y_pred
gbr_rec_result = gbr_rec_result.sort_values("y_pred", ascending=False)[:top_n]
gbr_rec_result = gbr_rec_result.merge(self.ml_train_set[['isbn_encoded', 'isbn', 'book_title', 'book_author']].drop_duplicates(), on='isbn_encoded')
gbr_rec_result = gbr_rec_result[['isbn', 'book_title', 'book_author']]
gbr_rec_result['user_id'] = user_id
gbr_rec_result = gbr_rec_result.reindex(columns=['user_id', 'isbn', 'book_title', 'book_author'])
return gbr_rec_result
def get_recommended_items_content(self, user_id, top_n):
""" Content-based recommendations """
most_liked_isbn = self.df_mf[self.df_mf['user_id'] == user_id].sort_values("rating", ascending=False)['isbn']
if most_liked_isbn.empty:
return pd.DataFrame() # Return empty DataFrame if user has no ratings
most_liked_isbn = most_liked_isbn.values[0]
if most_liked_isbn not in self.book_rec['isbn'].values:
predictions = self.book_info.sort_values("rating_count", ascending=False)[:top_n]
predictions['user_id'] = user_id
return predictions[['user_id', 'isbn', 'book_title', 'book_author']]
else:
idx = self.book_rec[self.book_rec['isbn'] == most_liked_isbn].index[0]
sim_scores = list(enumerate(self.cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)[1:top_n+1]
book_indices = [i[0] for i in sim_scores]
recommend_books = self.book_rec.iloc[book_indices]['isbn']
predictions = self.book_info[self.book_info['isbn'].isin(recommend_books)]
predictions['user_id'] = user_id
return predictions[['user_id', 'isbn', 'book_title', 'book_author']]
book_recommender = BookRecommender(df_mf, book_info, book_rec, strat_train_set, cosine_sim)# randome user_ids
unique_user_ids = df_mf['user_id'].unique()
np.random.shuffle(unique_user_ids)
print(unique_user_ids[:20])
user_id = 28255
top_n = 10
mf_rec_result = book_recommender.get_recommended_items_mf(user_id, top_n)
mf_rec_result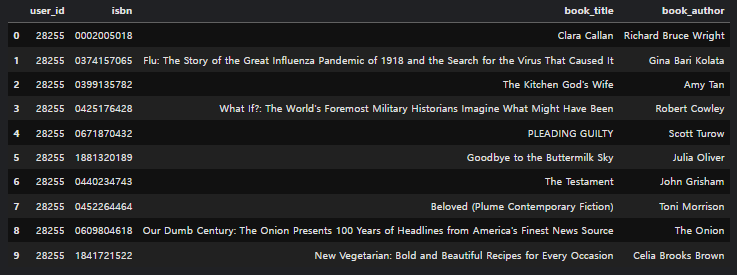
ml_rec_result = book_recommender.get_recommended_items_ml(user_id, top_n)
ml_rec_result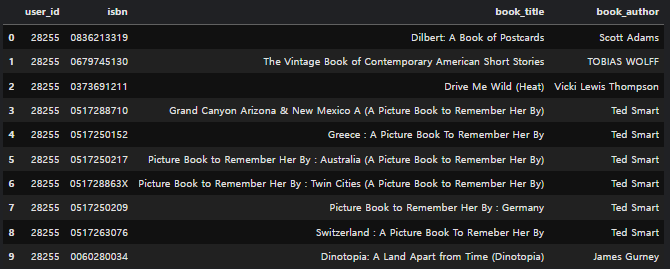
content_rec_result = book_recommender.get_recommended_items_content(user_id, top_n)
content_rec_result
'개인 활동(공부) > 강의' 카테고리의 다른 글
| Kaggle 데이터를 활용한 개인화 추천시스템(7) (0) | 2024.12.10 |
|---|---|
| Kaggle 데이터를 활용한 개인화 추천시스템(5) (2) | 2024.12.10 |
| Kaggle 데이터를 활용한 개인화 추천시스템(4) (1) | 2024.12.05 |
| Kaggle 데이터를 활용한 개인화 추천시스템(3) (3) | 2024.12.05 |
| Kaggle 데이터를 활용한 개인화 추천시스템(2) (2) | 2024.12.05 |
최종 추천모델 클래스 구성
- Matrix Factorization(SVD), Machine Learning(GBR), Content+Poupularity 추천을 생성하는 코드
SVD Recommender
python
import pandas as pd
from surprise import Dataset, Reader
from surprise import SVD
from sklearn.ensemble import GradientBoostingRegressor
class SVDRecommender:
def __init__(self, df_mf):
self.df_mf = df_mf
self.svd_model = self.fit_svd_model()
def fit_svd_model(self):
# Preprocessing
df_mf = self.df_mf[['user_id', 'isbn', 'rating']].drop_duplicates()
user_list = df_mf.groupby("user_id").size().reset_index(name='review_cnt')
user_list = user_list[user_list['review_cnt'] >= 30]
df_mf = df_mf[df_mf['user_id'].isin(user_list['user_id'])]
# Ensure reader is defined
reader = Reader(rating_scale=(1, 5)) # Adjust scale as needed
# Train
train_data = Dataset.load_from_df(df_mf[['user_id', 'isbn', 'rating']], reader)
trainset = train_data.build_full_trainset()
svd = SVD()
svd.fit(trainset)
return svdGBR Recommender
python
class GBRRecommender:
def __init__(self, ml_train_set, book_info, user_info):
self.ml_train_set = ml_train_set
self.book_info = book_info
self.user_info = user_info
self.gbr_model = self.fit_gbr_model()
def fit_gbr_model(self):
# Prepare data for GBR fitting
df_mf = self.preprocessing(self.ml_train_set)
# Train
X_train, y_train = self.split_data(df_mf)
gbr_model = GradientBoostingRegressor(random_state=42)
gbr_model.fit(X_train, y_train)
return gbr_model
def preprocessing(self, df):
df_mf = df[['user_id', 'isbn', 'rating']].drop_duplicates()
user_list = df_mf.groupby("user_id").size().reset_index(name='review_cnt')
user_list = user_list[user_list['review_cnt'] >= 30]
df_mf = df_mf[df_mf['user_id'].isin(user_list['user_id'])]
merged_df = df_mf.merge(self.book_info, on='isbn')\
.merge(self.user_info[['user_id', 'age']].drop_duplicates(), on='user_id')
return self.encode_categorical_columns(merged_df)
def encode_categorical_columns(self, df):
"""Encode categorical columns in the DataFrame."""
categorical_columns = ['isbn', 'book_author', 'category']
for column in categorical_columns:
df[f'{column}_encoded'] = df[column].astype('category').cat.codes
return df
def split_data(self, df):
features = ['age', 'isbn_encoded', 'book_author_encoded', 'year_of_publication',
'rating_mean', 'rating_count', 'category_encoded']
# Check if all features exist in the DataFrame
missing_features = [feature for feature in features if feature not in df.columns]
if missing_features:
print(f"Missing features: {missing_features}")
raise KeyError(f"None of {missing_features} are in the input DataFrame")
X = df[features]
y = df['rating']
return X, yFinal Book Recommender with SVD, GBR, Content&Popularity
- SVD Recommender와 GBR Recommender 클래스를 상속받아 Book Recommender 에서는 3개의 알고리즘을 이용해 추천셋 생성
python
class BookRecommender(SVDRecommender, GBRRecommender):
def __init__(self, df_mf, book_info, book_rec, ml_train_set, cosine_sim):
SVDRecommender.__init__(self, df_mf)
GBRRecommender.__init__(self, ml_train_set, book_info, ml_train_set[['user_id', 'age']].drop_duplicates())
self.book_info = book_info
self.book_rec = book_rec
self.cosine_sim = cosine_sim
def get_recommended_items_mf(self, user_id, top_n):
"""Matrix Factorization based recommendations"""
user_reviewed_iid = self.df_mf[self.df_mf['user_id'] == user_id]['isbn']
iid_to_est = self.df_mf[~self.df_mf['isbn'].isin(user_reviewed_iid)]['isbn'].drop_duplicates()
testset = [(user_id, iid, None) for iid in iid_to_est]
predictions = self.svd_model.test(testset)
predictions = pd.DataFrame(predictions)[['uid', 'iid', 'est']]
predictions.columns = ['user_id', 'isbn', 'predicted_rating']
predictions['predicted_rank'] = predictions['predicted_rating'].rank(method='first', ascending=False)
predictions = predictions.sort_values("predicted_rank")[:top_n]
predictions = predictions.merge(self.book_info, on='isbn')
return predictions[['user_id', 'isbn', 'book_title', 'book_author']]
def get_recommended_items_ml(self, user_id, top_n):
"""Machine Learning (GBR) based recommendations"""
user_reviewed_iid = self.df_mf[self.df_mf['user_id'] == user_id]['isbn']
iid_to_est = self.df_mf[~self.df_mf['isbn'].isin(user_reviewed_iid)]['isbn'].drop_duplicates()
ml_test_set = self.ml_train_set[self.ml_train_set['isbn'].isin(iid_to_est)]
user_age = self.ml_train_set[self.ml_train_set['user_id'] == user_id]['age'].unique()
features = ['age', 'isbn_encoded', 'book_author_encoded', 'year_of_publication',
'rating_mean', 'rating_count', 'category_encoded']
X = ml_test_set[features].query("age == @user_age")
y_pred = self.gbr_model.predict(X)
gbr_rec_result = X.copy()
gbr_rec_result['y_pred'] = y_pred
gbr_rec_result = gbr_rec_result.sort_values("y_pred", ascending=False)[:top_n]
gbr_rec_result = gbr_rec_result.merge(self.ml_train_set[['isbn_encoded', 'isbn', 'book_title', 'book_author']].drop_duplicates(), on='isbn_encoded')
gbr_rec_result = gbr_rec_result[['isbn', 'book_title', 'book_author']]
gbr_rec_result['user_id'] = user_id
gbr_rec_result = gbr_rec_result.reindex(columns=['user_id', 'isbn', 'book_title', 'book_author'])
return gbr_rec_result
def get_recommended_items_content(self, user_id, top_n):
""" Content-based recommendations """
most_liked_isbn = self.df_mf[self.df_mf['user_id'] == user_id].sort_values("rating", ascending=False)['isbn']
if most_liked_isbn.empty:
return pd.DataFrame() # Return empty DataFrame if user has no ratings
most_liked_isbn = most_liked_isbn.values[0]
if most_liked_isbn not in self.book_rec['isbn'].values:
predictions = self.book_info.sort_values("rating_count", ascending=False)[:top_n]
predictions['user_id'] = user_id
return predictions[['user_id', 'isbn', 'book_title', 'book_author']]
else:
idx = self.book_rec[self.book_rec['isbn'] == most_liked_isbn].index[0]
sim_scores = list(enumerate(self.cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)[1:top_n+1]
book_indices = [i[0] for i in sim_scores]
recommend_books = self.book_rec.iloc[book_indices]['isbn']
predictions = self.book_info[self.book_info['isbn'].isin(recommend_books)]
predictions['user_id'] = user_id
return predictions[['user_id', 'isbn', 'book_title', 'book_author']]
book_recommender = BookRecommender(df_mf, book_info, book_rec, strat_train_set, cosine_sim)
python
# randome user_ids
unique_user_ids = df_mf['user_id'].unique()
np.random.shuffle(unique_user_ids)
print(unique_user_ids[:20])
python
user_id = 28255
top_n = 10
mf_rec_result = book_recommender.get_recommended_items_mf(user_id, top_n)
mf_rec_result
python
ml_rec_result = book_recommender.get_recommended_items_ml(user_id, top_n)
ml_rec_result
python
content_rec_result = book_recommender.get_recommended_items_content(user_id, top_n)
content_rec_result'개인 활동(공부) > 강의' 카테고리의 다른 글
| Kaggle 데이터를 활용한 개인화 추천시스템(7) (0) | 2024.12.10 |
|---|---|
| Kaggle 데이터를 활용한 개인화 추천시스템(5) (2) | 2024.12.10 |
| Kaggle 데이터를 활용한 개인화 추천시스템(4) (1) | 2024.12.05 |
| Kaggle 데이터를 활용한 개인화 추천시스템(3) (3) | 2024.12.05 |
| Kaggle 데이터를 활용한 개인화 추천시스템(2) (2) | 2024.12.05 |