
전국 커피 전문점
#set(data["상권업종대분류명"])
set(data["상권업종중분류명"])
# 카페만 뽑아냅니다.
df_coffee = data[data["상권업종중분류명"] == "커피점/카페"]
# index를 다시 세팅합니다.
df_coffee.index = range(len(df_coffee))
print("전국 커피 전문점 점포 수 : ", len(df_coffee))
df_coffee
서울 내 커피 전문점
set(data["시도명"])
# 카페 중에 "서울"에 위치하고 있는 점포만 뽑아냅니다.
df_seoul_coffee = data[(data["상권업종중분류명"] == "커피점/카페") & (data["시도명"] == "서울특별시")]
df_seoul_coffee.index = range(len(df_seoul_coffee))
print('서울시 내 커피 전문점 점포 수 :', len(df_seoul_coffee))
df_seoul_coffee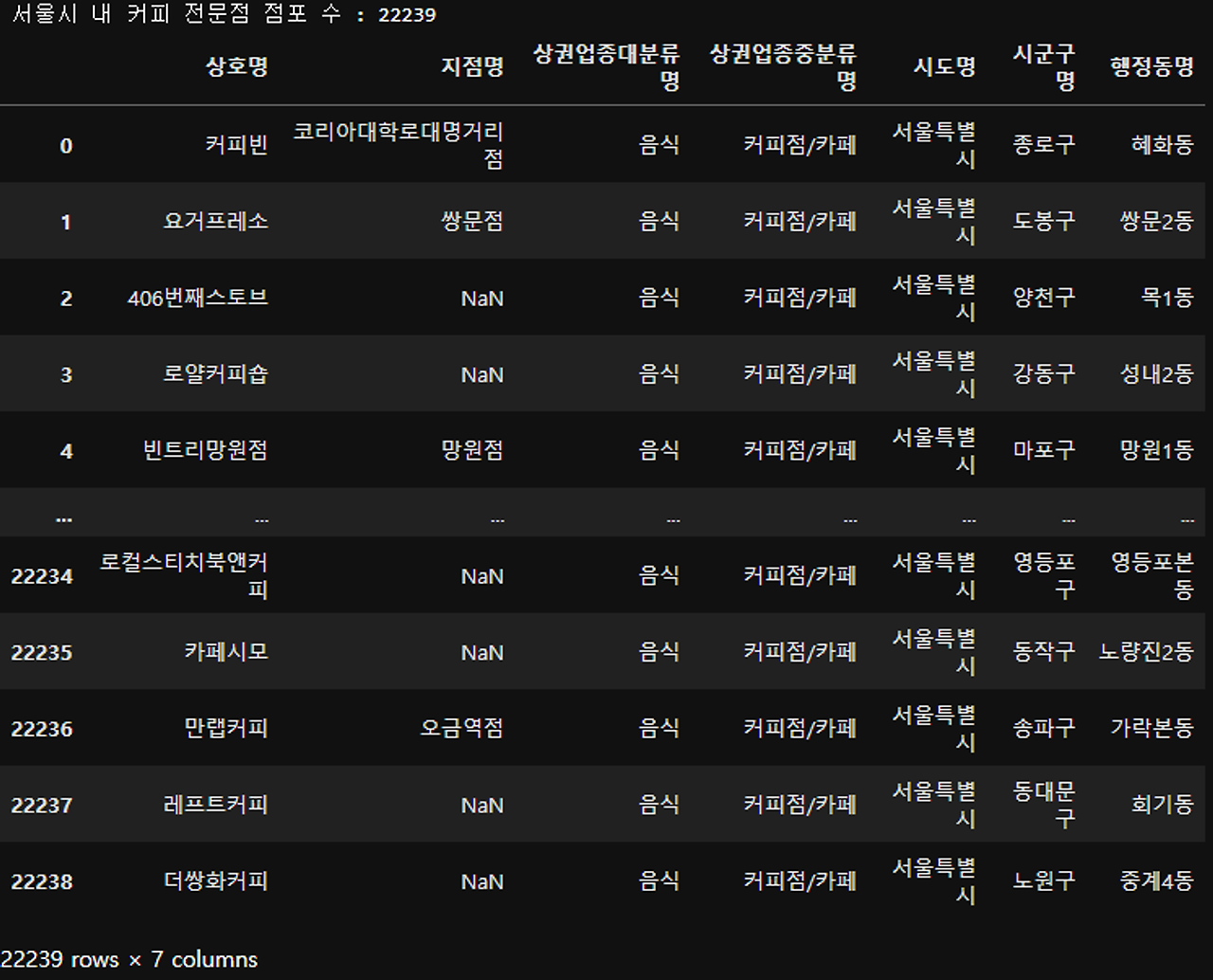
전국 스타벅스
df_coffee["상호명"].str.contains("스타벅스")
# 이번엔 전국에 있는 스타벅스를 뽑아냅니다.
df_starbucks = df_coffee[df_coffee["상호명"].str.contains("스타벅스")]
df_starbucks.index = range(len(df_starbucks))
print('전국 스타벅스 점포 수 :', len(df_starbucks))
df_starbucks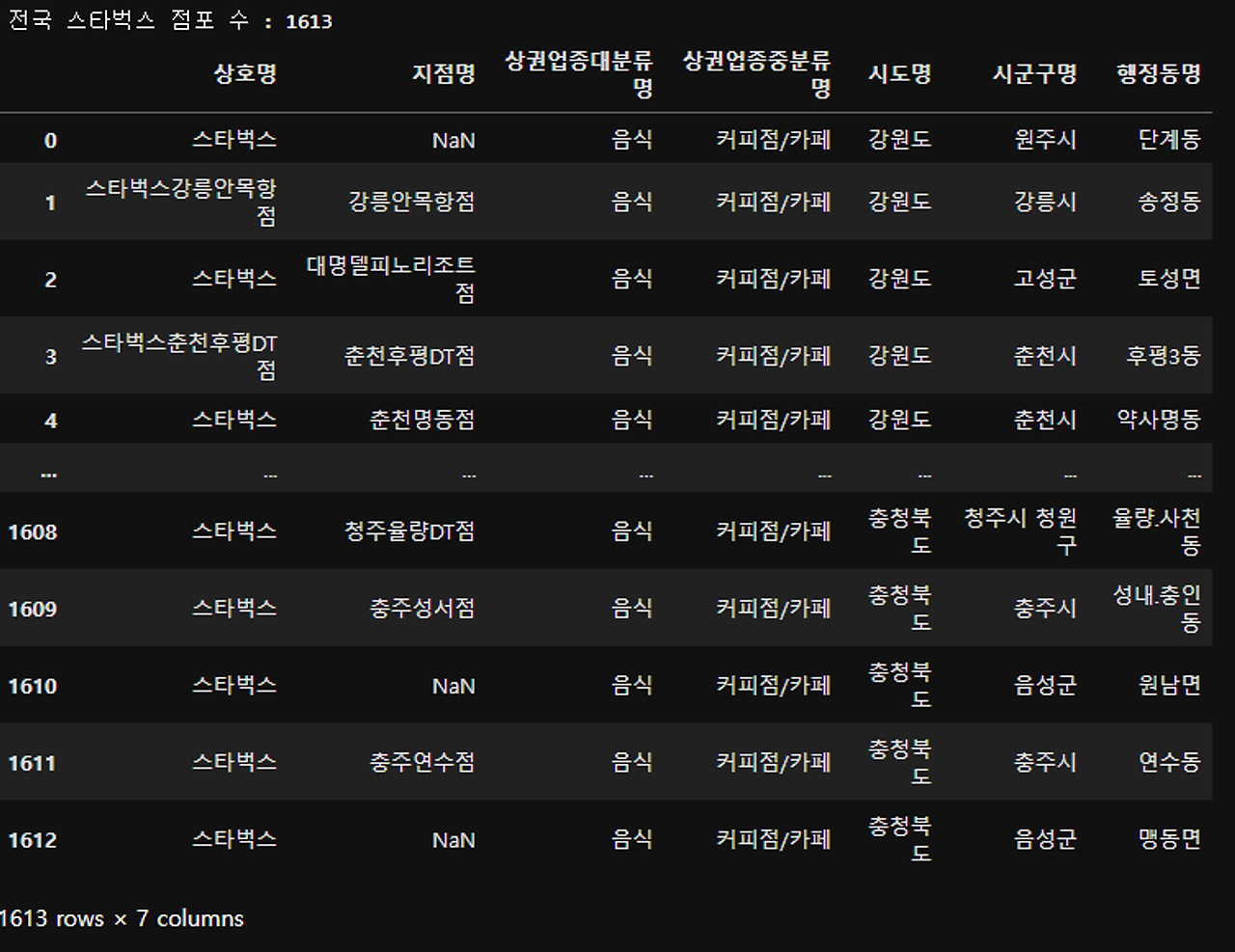
서울 스타벅스
# 이번엔 서울에 있는 스타벅스를 뽑아냅니다.
df_seoul_starbucks = df_starbucks[df_starbucks["시도명"] == "서울특별시"]
df_seoul_starbucks.index = range(len(df_seoul_starbucks))
print('서울시 내 스타벅스 점포 수 :', len(df_seoul_starbucks))
df_seoul_starbucks.head()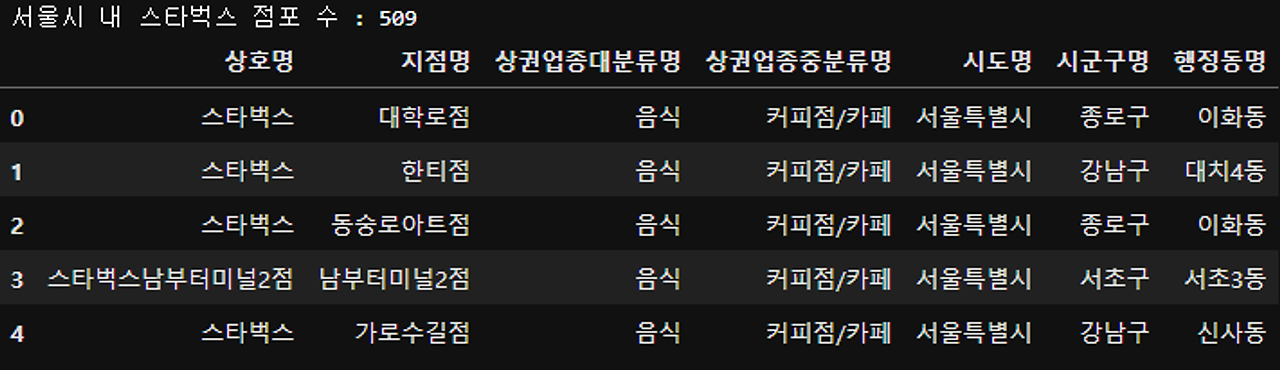
전국 이디야
# 이번엔 전국에 있는 이디야를 뽑아냅니다.
df_ediya = df_coffee[df_coffee["상호명"].str.contains("이디야")]
df_ediya.index = range(len(df_ediya))
print('전국 이디야 점포 수 :', len(df_ediya))
df_ediya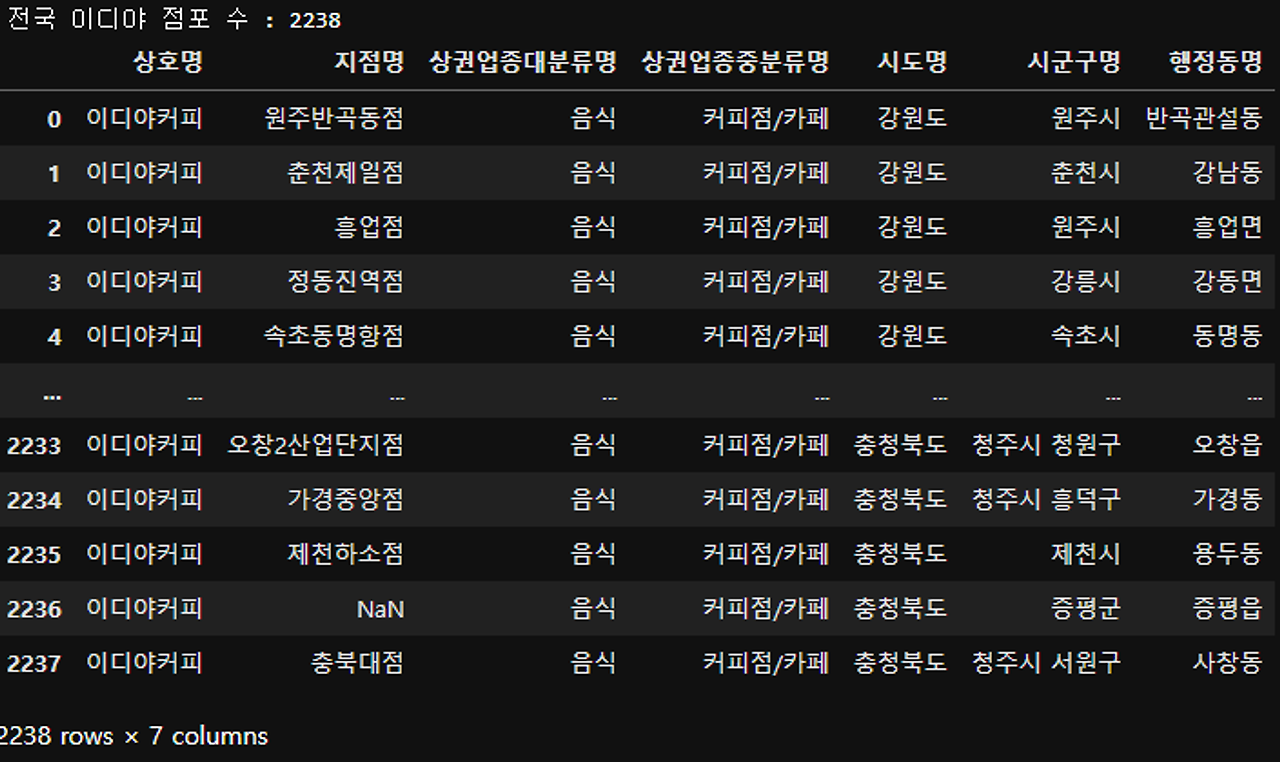
서울 이디야
# 이번엔 서울에 있는 이디야를 뽑아냅니다.
df_seoul_ediya = df_ediya[df_ediya["시도명"] == "서울특별시"]
df_seoul_ediya.index = range(len(df_seoul_ediya))
print('서울시 내 이디야 점포 수 :', len(df_seoul_ediya))
df_seoul_ediya.head()
'빅데이터 분석가 양성과정 > Python' 카테고리의 다른 글
| 공공데이터 분석(커피전문점) - 시각화 (0) | 2024.07.08 |
|---|---|
| 공공데이터 분석(커피전문점) - 유명 브랜드별 비율 비교하기 (0) | 2024.07.08 |
| 공공데이터 분석(커피전문점) - Load Data (0) | 2024.07.08 |
| Seaborn - Kaggle Survey EDA(2) (0) | 2024.07.08 |
| Seaborn - Kaggle Survey EDA(1) (0) | 2024.07.08 |