
6. 범주형 데이터의 요약(탐색)
- 수준 별로 데이터 분류하기
- 수준 별로 데이터 갯수 세기 (count)
- 절대 빈도: 절대 갯수, 상대 빈도: 각 수준의 비율(%)
- 시각화 하기 (빈도표, frequency table)
6.1. 수준 별로 데이터 분류하기
data = {
'year': ['2017', '2017', '2019', '2020', '2021', '2021'],
'grade': ['C', 'C', 'B', 'A', 'B', 'E'],
}
df = pd.DataFrame(data)df1 = df.groupby("grade").count()
df2 = df.groupby("year").count()df1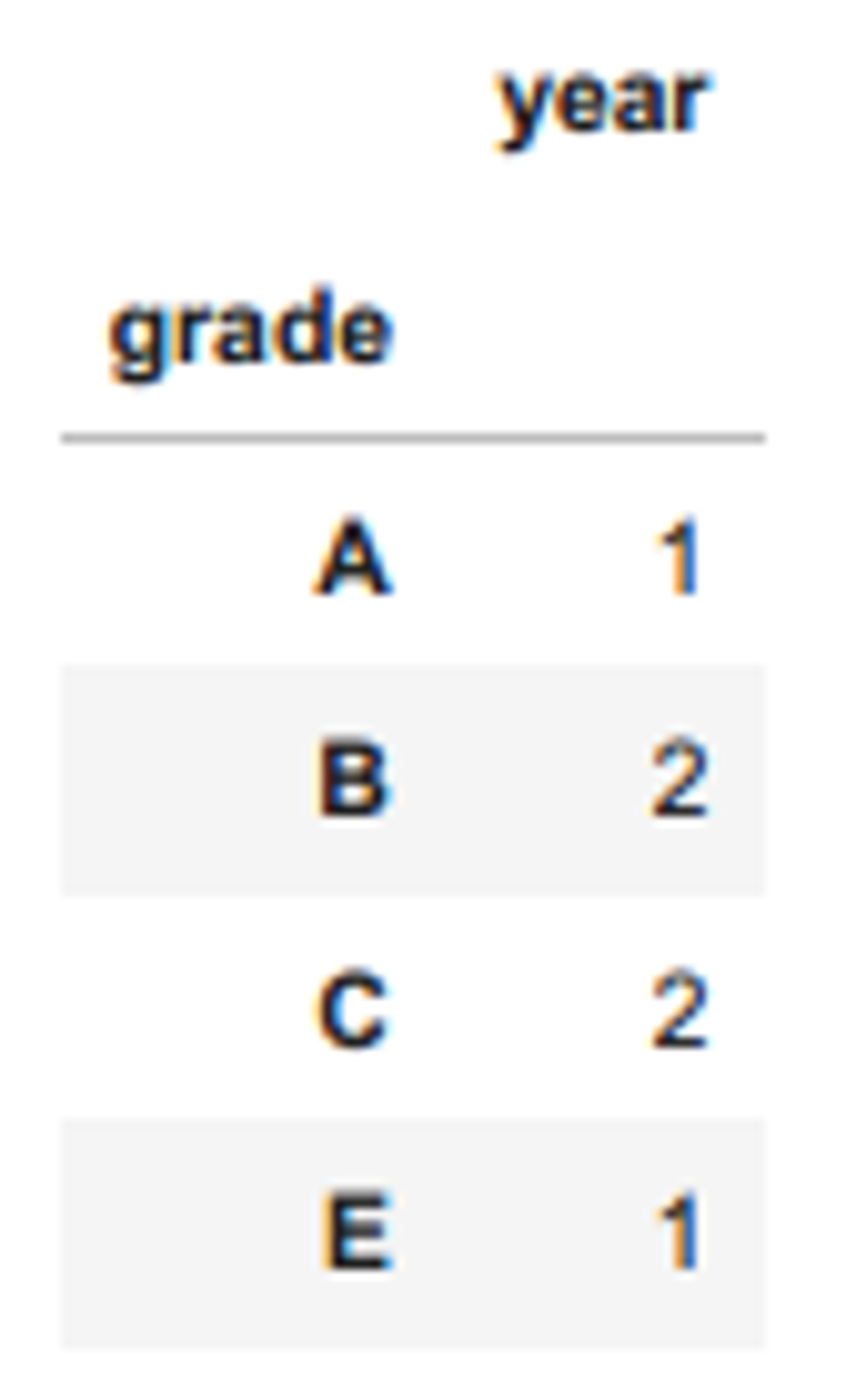
df2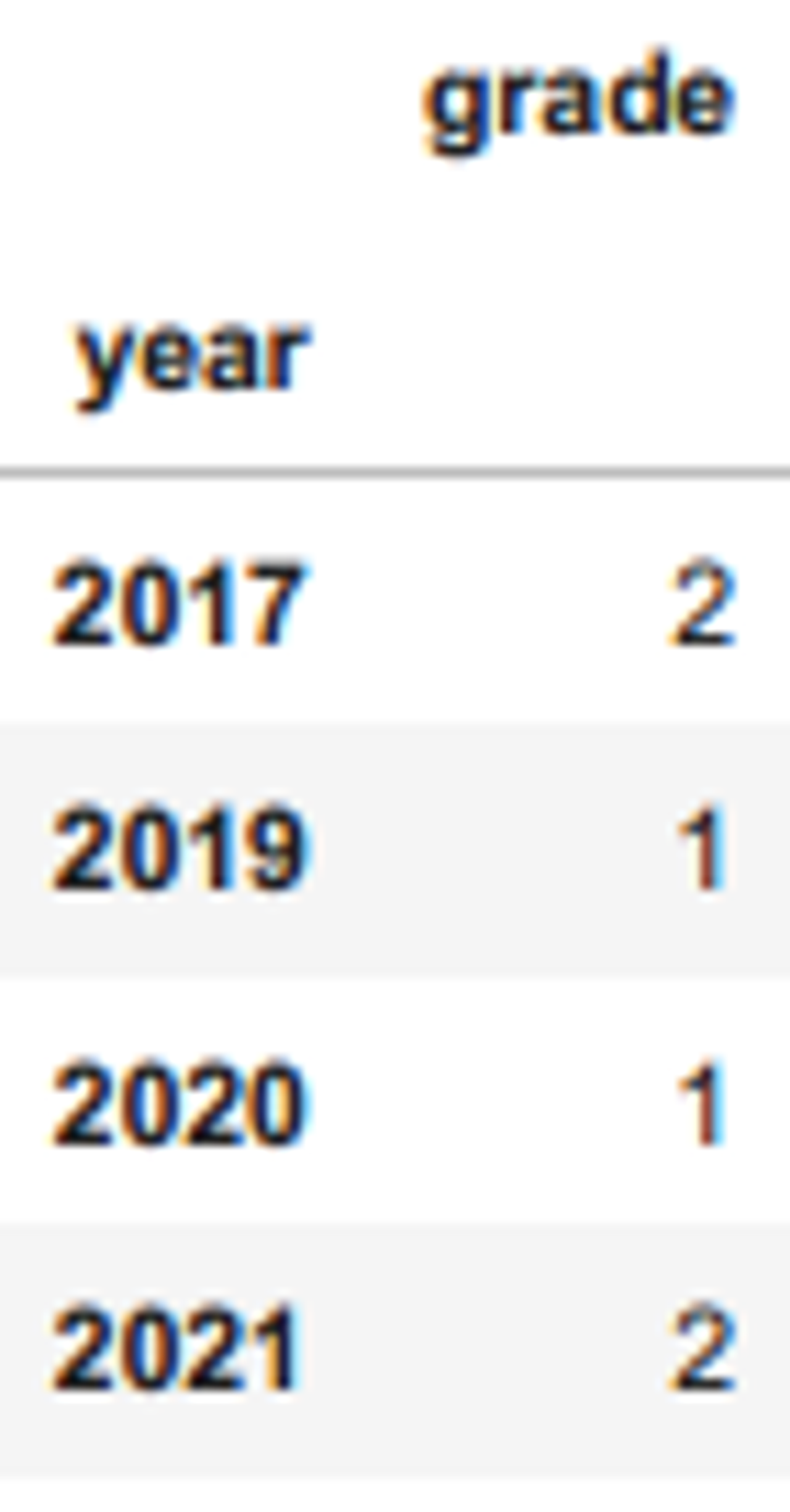
6.2. 수준 별로 데이터 갯수 세기 (count)
- size : 사이즈 반환
- count() : 데이터가 없는 경우를 뺀 사이즈 반환
- unique(): 유일한 값만 반환
- value_counts(): 데이터가 없는 경우를 제외하고, 각 값의 갯수를 반환
df['year'].value_counts()
df['year'].sizedf['year'].count()df['year'].unique()
7. 분석 타입에 따른 그래프 종류 이해: 범주형 데이터 분석을 위해 주로 사용되는 그래프 종류
- 막대 그래프 (절대 빈도)
- 원 그래프 (상대 빈도)
iplot() 사용 전 항상 사전 선언해줘야 함
import chart_studio.plotly as py
import cufflinks as cf
cf.go_offline(connected=True)
import pandas as pd# 다시 사전 작업
data = {
'year': ['2017', '2017', '2019', '2020', '2021', '2021'],
'grade': ['C', 'C', 'B', 'A', 'B', 'E'],
}
df = pd.DataFrame(data)
df1 = df.groupby("grade").count()
df2 = df.groupby("year").count()7.1. 막대그래프
iplot 으로 그려보기
df2.iplot(kind='bar')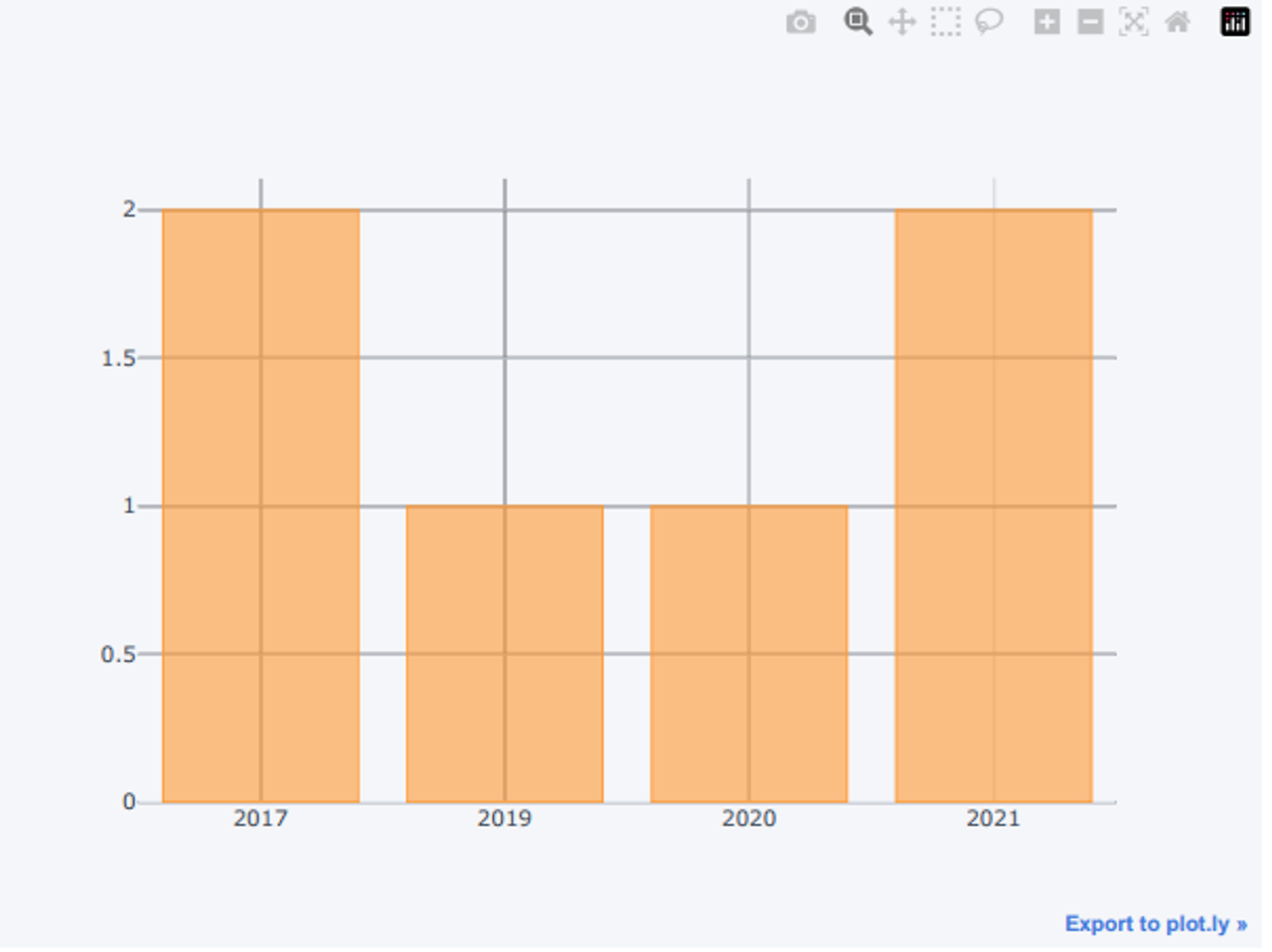
plotly.graph_objects 로 그려보기
df1
df2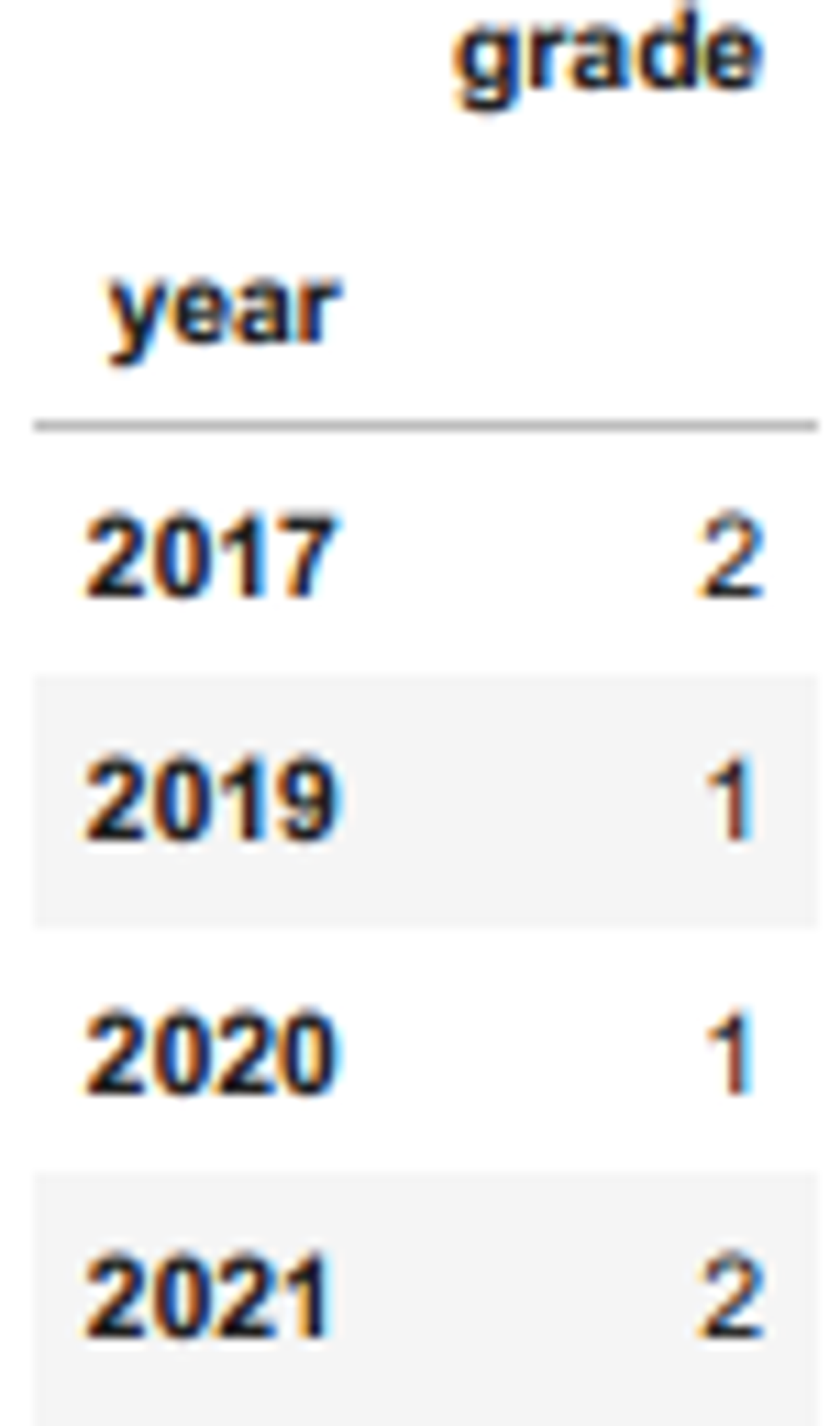
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(
go.Bar(
x=df1.index, y=df1['year'], name='A'
)
)
fig.show()
7.2. 원 그래프
iplot 으로 그려보기
- iplot(kind='pie') 시에는 labels에 lavels(수준)으로 분류될 컬럼 명, values에 각 수준(분류)의 값이 될 카운트 값을 가진 컬럼 명을 넣어 줘야 함
df1 = df1.reset_index() # 인덱스로 되어 있는 컬럼을 컬럼으로 바꿔줌
df1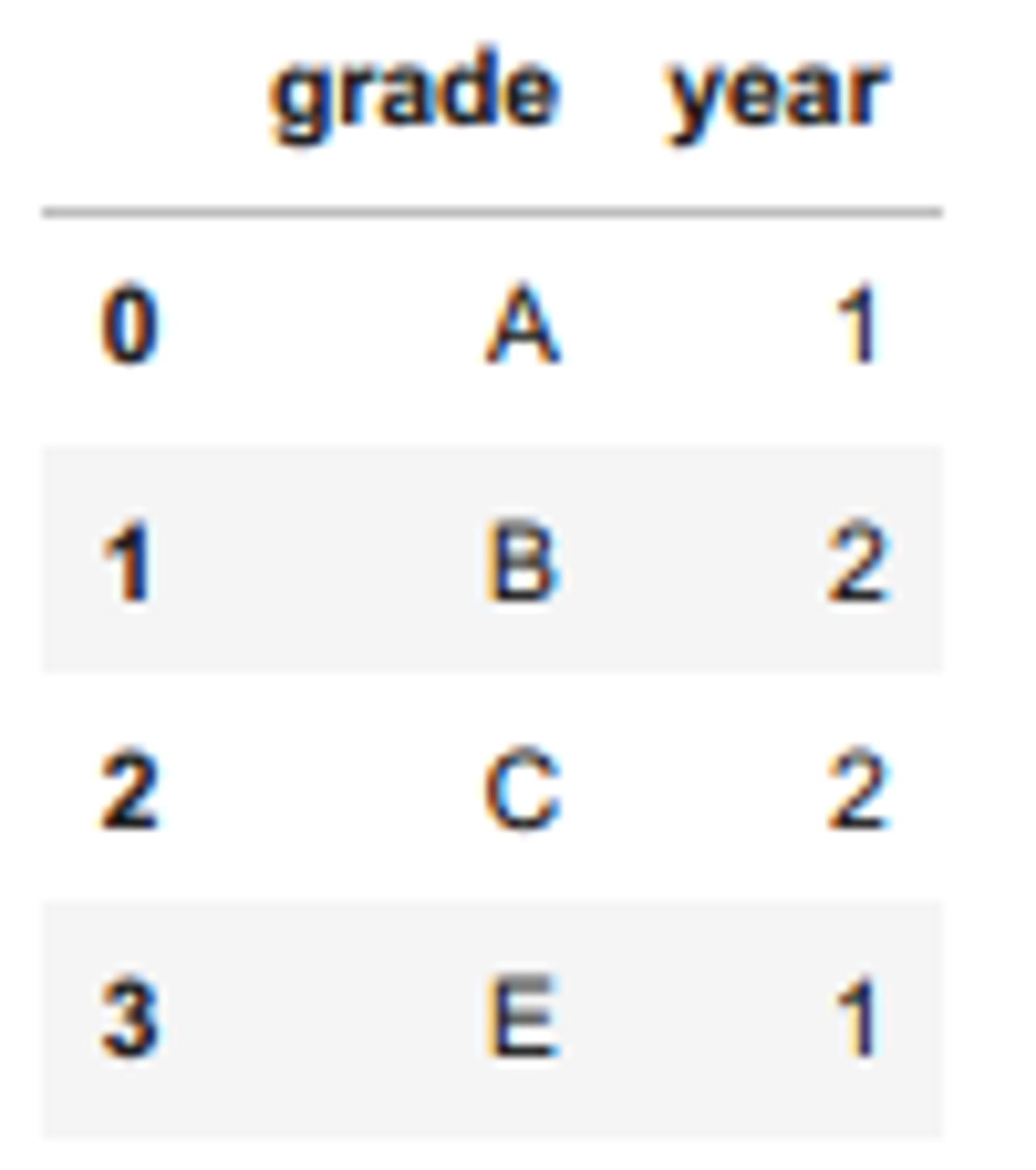
df1.iplot(kind='pie', labels='grade', values='year') # 보통 원 그래프를 통해 상대빈도 값을 확인
plotly.graph_objects 로 그려보기
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(
go.Pie(
labels=df1['grade'], values=df1['year']
)
)
fig.show()
'빅데이터 분석가 양성과정 > Python' 카테고리의 다른 글
| 시각화 이용한 탐색적 데이터 분석(6) (1) | 2024.07.08 |
|---|---|
| 시각화 이용한 탐색적 데이터 분석(5) (0) | 2024.07.08 |
| 시각화 이용한 탐색적 데이터 분석(3) (0) | 2024.07.08 |
| 시각화 이용한 탐색적 데이터 분석(2) (1) | 2024.07.08 |
| 시각화 이용한 탐색적 데이터 분석(1) (1) | 2024.07.08 |