
2. 데이터 분류 이해
- 데이터를 분석, 시각화, 예측하는 전반적인 과정에서 데이터에 대한 큰 그림을 이해하는 것이 도움이 됨
데이터는 크게 (1) 수치형, (2) 범주형 데이터로 나눌 수 있음
수치형 데이터
- 연속형(continuous) 데이터: 특정한 범위 안에 어떤 값(정수와 부동소숫점)이든 가질 수 있는 데이터
- 이산(discrete) 데이터: 횟수와 같은 정수만 가질 수 있는 데이터
범주형 데이터
- 명목형(nominal) 데이터: 카테고리, 타입, 항목 등 데이터 분류를 위해 이미 정해진 값이 있는 데이터, 데이터가 가질 수 있는 값을 수준(levels) 라고 부름
- 순서형(ordinal) 데이터: 이미 정해진 값 사이의 순서 관계가 있는 데이터

- 1반(1), 2반(2), 3반(3)을 나타내는 데이터가 있다면? 순서형 데이터일까요?
- 1보다 2가 더 좋거나, 더 큰 의미를 가지는 것이 아니므로, 명목형 데이터라고 봐야 함
3. 수치형 데이터의 요약(탐색)
다섯 수치 요약 (5 number summary) 확인하기
- 최소값(minimum), 제1사분위수, 중간값(mediam)=제2사분위수, 제3사분위수, 최대값(maximum) 확인하기
분위수(quartile)
- 자료 크기 순서에 따른 위치값(경계값)
사분위수
- Q1: 제1사분위수 (25%에 해당하는 값)
- Q2: 제2사분위수 (50%에 해당하는 값, 중간값)
- Q3: 제3사분위수 (75%에 해당하는 값)
- Q4: 제4사분위수 (100%에 해당하는 값, 최대값)
import numpy as np
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5, 6],
'C': [1, 2, 3, 4, 5, 100]
})
df.head()

평균과 중간값
- 평균은 이상치 특잇값(outlier)에 큰 영향을 받음
- EDA 에서는 특잇값에 큰 영향을 받지 않는 중간값을 선호
- 대부분의 값과 매우 다른 값
- 다양한 특잇값 검출 기법이 있긴 하지만, 주관적인 측면이 강하므로 데이터 탐색을 통해, 확인하는 것이 가장 좋음
중간값 계산 방법
- 데이터가 홀수개 있다면, 중간에 위치한 값을 채택
- 데이터가 짝수개 있다면, 중간에 위치한 두 값의 평균을 선택
- 예: 위 예에서 3과 4의 평균이 3.5
df.describe()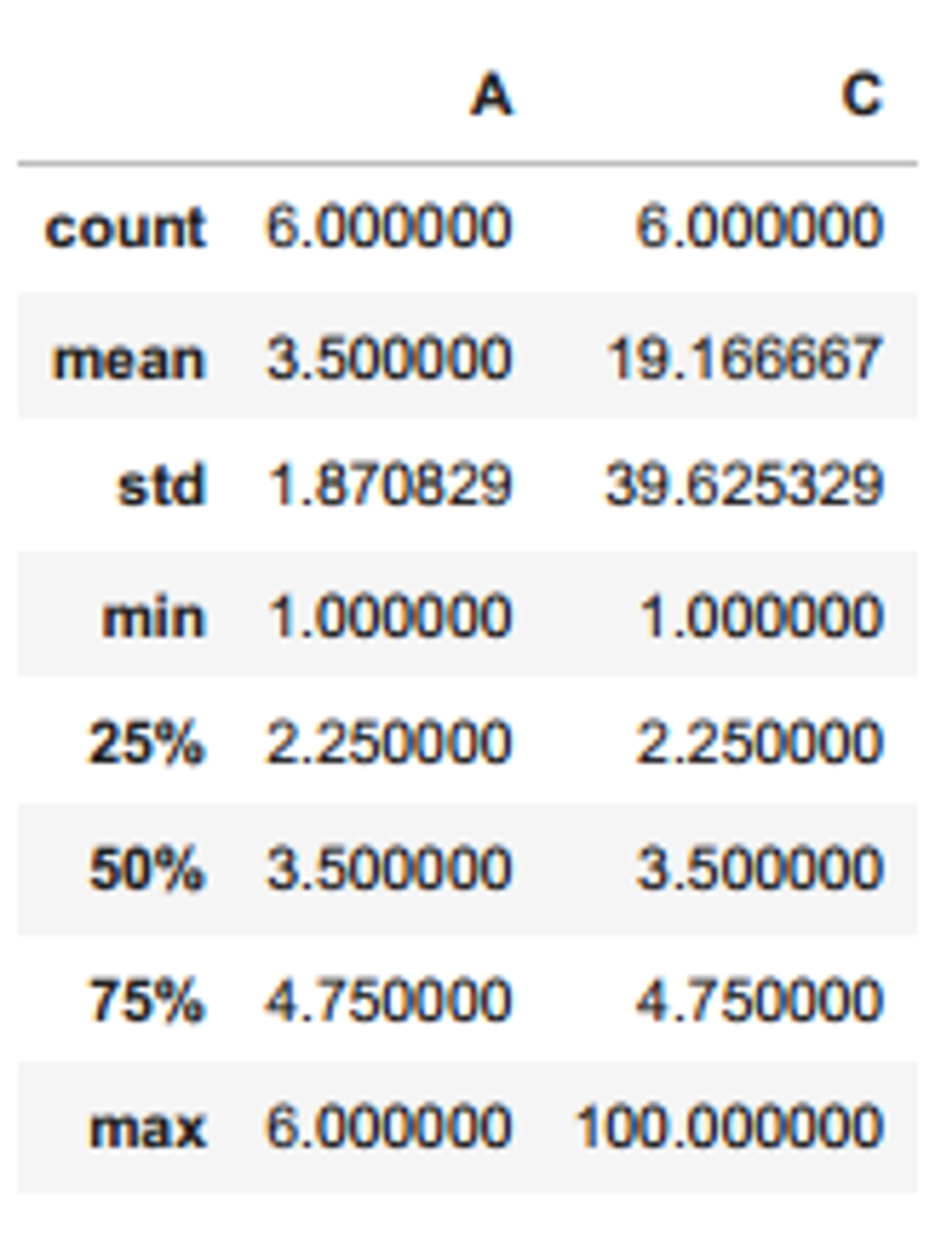
'빅데이터 분석가 양성과정 > Python' 카테고리의 다른 글
| 시각화 이용한 탐색적 데이터 분석(4) (0) | 2024.07.08 |
|---|---|
| 시각화 이용한 탐색적 데이터 분석(3) (0) | 2024.07.08 |
| 시각화 이용한 탐색적 데이터 분석(1) (1) | 2024.07.08 |
| plotly - 막대 그래프 / 세부 요소 변경 (1) | 2024.07.08 |
| plotly - 선 그래프 (0) | 2024.07.08 |