
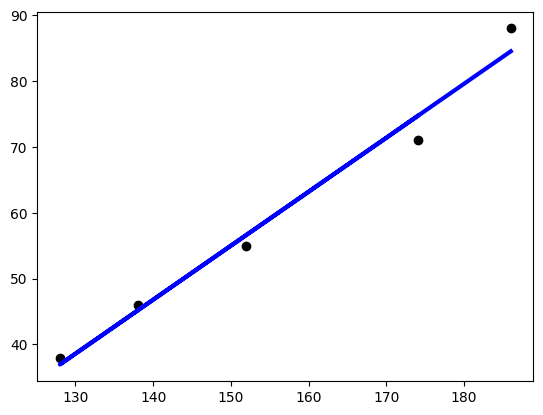
예제1 ) 키, 몸무게 / 당뇨병
- 인간의 키와 몸무게 학습
- 키가 165일때 몸무게 예측
import matplotlib.pylab as plt
from sklearn import linear_model
reg = linear_model.LinearRegression()
X = [[174],[152],[138],[128],[186]]
y = [71,55,46,38,88]
reg.fit(X,y)
print(reg.predict([[165]]))
# 학습 데이터와 y 값을 산포도로 그린다.
plt.scatter(X, y, color = 'black')
# 학습 데이터를 입력으로 하여 예측값을 계산한다.
y_pred = reg.predict(X)
# 학습 데이터와 예측값으로 선 그래프를 그린다.
# 계산된 기울기와 y 절편을 가지는 직선이 그려진다.
plt.plot(X, y_pred, color = 'blue', linewidth = 3)
plt.show()
[67.30998637]
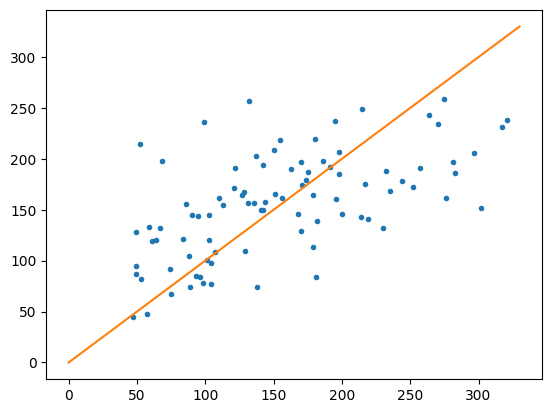
당뇨병 예제
import matplotlib.pylab as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn import datasets
diabetes = datasets.load_diabetes()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, test_size = 0.2, random_state = 0)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
plt.plot(y_test, y_pred, '.')
x = np.linspace(0,330,100)
y = x
plt.plot(x,y)
plt.show()
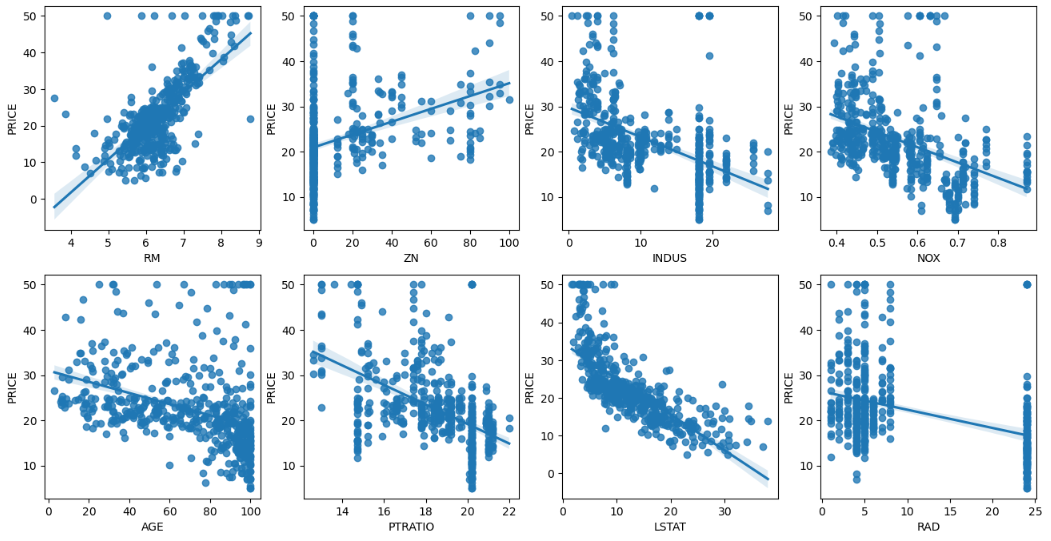
예제2) 보스턴 주택가격
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from scipy import stats
from sklearn.datasets import load_boston
%matplotlib inline
# boston 데이타셋 로드
boston = load_boston()
# boston 데이타셋 DataFrame 변환
bostonDF = pd.DataFrame(boston.data , columns = boston.feature_names)
# boston dataset의 target array는 주택 가격임. 이를 PRICE 컬럼으로 DataFrame에 추가함.
bostonDF['PRICE'] = boston.target
print('Boston 데이타셋 크기 :',bostonDF.shape)
bostonDF.head()
Boston 데이타셋 크기 : (50 6, 14)


각 컬럼별로 주택가격에 미치는 영향도를 조사
- 피처/타겟값 상관관계 파악 - seaborn의 regplot 이용하면 산점도와 선형 회귀 직선을 함께 나타내준다.
# 2개의 행과 4개의 열을 가진 subplots를 이용. axs는 4x2개의 ax를 가짐.
fig, axs = plt.subplots(figsize=(16,8) , ncols=4 , nrows=2)
lm_features = ['RM','ZN','INDUS','NOX','AGE','PTRATIO','LSTAT','RAD']
for i , feature in enumerate(lm_features):
row = int(i/4)
col = i%4
# 시본의 regplot을 이용해 산점도와 선형 회귀 직선을 함께 표현
sns.regplot(x=feature , y='PRICE',data=bostonDF , ax=axs[row][col])
학습과 테스트 데이터 세트로 분리하고 학습/예측/평가 수행
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error , r2_score
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
X_train , X_test , y_train , y_test = train_test_split(X_data , y_target ,test_size=0.3, random_state=156)
# Linear Regression OLS로 학습/예측/평가 수행.
lr = LinearRegression()
lr.fit(X_train ,y_train )
y_preds = lr.predict(X_test)
mse = mean_squared_error(y_test, y_preds)
rmse = np.sqrt(mse)
print('MSE : {0:.3f} , RMSE : {1:.3F}'.format(mse , rmse))
print('Variance score : {0:.3f}'.format(r2_score(y_test, y_preds)))
MSE : 17.297 , RMSE : 4.159
Variance score : 0.757
print('절편 값:',lr.intercept_)
print('회귀 계수값:', np.round(lr.coef_, 1))
절편 값: 40.99559517216464
회귀 계수값: [ -0.1 0.1 0. 3. -19.8 3.4 0. -1.7 0.4 -0. -0.9 0. -0.6]
- 회귀계수 : Nox(환경지수?) 값
회귀 계수(모델에 영향을 미치는 정도)가 큰 순서대로 정렬
# 회귀 계수를 큰 값 순으로 정렬하기 위해 Series로 생성. index가 컬럼명에 유의
coeff = pd.Series(data=np.round(lr.coef_, 1), index=X_data.columns )
coeff.sort_values(ascending=False)
RM 3.4
CHAS 3.0
RAD 0.4
ZN 0.1
INDUS 0.0
AGE 0.0
TAX -0.0
B 0.0
CRIM -0.1
LSTAT -0.6
PTRATIO -0.9
DIS -1.7
NOX -19.8
dtype: float64
Fold 셋으로 교차 검증을 수행하여 MSE, RMSE 구하기
from sklearn.model_selection import cross_val_score
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
lr = LinearRegression()
# cross_val_score( )로 5 Fold 셋으로 MSE 를 구한 뒤 이를 기반으로 다시 RMSE 구함.
neg_mse_scores = cross_val_score(lr, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
# cross_val_score(scoring="neg_mean_squared_error")로 반환된 값은 모두 음수
print(' 5 folds 의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 2))
print(' 5 folds 의 개별 RMSE scores : ', np.round(rmse_scores, 2))
print(' 5 folds 의 평균 RMSE : {0:.3f} '.format(avg_rmse))
5 folds 의 개별 Negative MSE scores: [-12.46 -26.05 -33.07 -80.76 -33.31]
5 folds 의 개별 RMSE scores : [3.53 5.1 5.75 8.99 5.77]
5 folds 의 평균 RMSE : 5.829
'빅데이터 분석가 양성과정 > Python - 머신러닝' 카테고리의 다른 글
| 회귀(Regression) - 규제 선형 회귀 (0) | 2024.07.12 |
|---|---|
| 회귀(Regression) - 다항 선형 회귀 (0) | 2024.07.12 |
| 회귀(Regression) - 선형 회귀 / 경사 하강법 (0) | 2024.07.12 |
| 실습) adult data 분류 (0) | 2024.07.11 |
| 머신러닝 분류 - 앙상블 러닝 (2) | 2024.07.11 |
예제1 ) 키, 몸무게 / 당뇨병
- 인간의 키와 몸무게 학습
- 키가 165일때 몸무게 예측
import matplotlib.pylab as plt
from sklearn import linear_model
reg = linear_model.LinearRegression()
X = [[174],[152],[138],[128],[186]]
y = [71,55,46,38,88]
reg.fit(X,y)
print(reg.predict([[165]]))
# 학습 데이터와 y 값을 산포도로 그린다.
plt.scatter(X, y, color = 'black')
# 학습 데이터를 입력으로 하여 예측값을 계산한다.
y_pred = reg.predict(X)
# 학습 데이터와 예측값으로 선 그래프를 그린다.
# 계산된 기울기와 y 절편을 가지는 직선이 그려진다.
plt.plot(X, y_pred, color = 'blue', linewidth = 3)
plt.show()
[67.30998637]
당뇨병 예제
import matplotlib.pylab as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn import datasets
diabetes = datasets.load_diabetes()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, test_size = 0.2, random_state = 0)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
plt.plot(y_test, y_pred, '.')
x = np.linspace(0,330,100)
y = x
plt.plot(x,y)
plt.show()
예제2) 보스턴 주택가격
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from scipy import stats
from sklearn.datasets import load_boston
%matplotlib inline
# boston 데이타셋 로드
boston = load_boston()
# boston 데이타셋 DataFrame 변환
bostonDF = pd.DataFrame(boston.data , columns = boston.feature_names)
# boston dataset의 target array는 주택 가격임. 이를 PRICE 컬럼으로 DataFrame에 추가함.
bostonDF['PRICE'] = boston.target
print('Boston 데이타셋 크기 :',bostonDF.shape)
bostonDF.head()
Boston 데이타셋 크기 : (50 6, 14)
각 컬럼별로 주택가격에 미치는 영향도를 조사
- 피처/타겟값 상관관계 파악 - seaborn의 regplot 이용하면 산점도와 선형 회귀 직선을 함께 나타내준다.
# 2개의 행과 4개의 열을 가진 subplots를 이용. axs는 4x2개의 ax를 가짐.
fig, axs = plt.subplots(figsize=(16,8) , ncols=4 , nrows=2)
lm_features = ['RM','ZN','INDUS','NOX','AGE','PTRATIO','LSTAT','RAD']
for i , feature in enumerate(lm_features):
row = int(i/4)
col = i%4
# 시본의 regplot을 이용해 산점도와 선형 회귀 직선을 함께 표현
sns.regplot(x=feature , y='PRICE',data=bostonDF , ax=axs[row][col])
학습과 테스트 데이터 세트로 분리하고 학습/예측/평가 수행
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error , r2_score
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
X_train , X_test , y_train , y_test = train_test_split(X_data , y_target ,test_size=0.3, random_state=156)
# Linear Regression OLS로 학습/예측/평가 수행.
lr = LinearRegression()
lr.fit(X_train ,y_train )
y_preds = lr.predict(X_test)
mse = mean_squared_error(y_test, y_preds)
rmse = np.sqrt(mse)
print('MSE : {0:.3f} , RMSE : {1:.3F}'.format(mse , rmse))
print('Variance score : {0:.3f}'.format(r2_score(y_test, y_preds)))
MSE : 17.297 , RMSE : 4.159
Variance score : 0.757
print('절편 값:',lr.intercept_)
print('회귀 계수값:', np.round(lr.coef_, 1))
절편 값: 40.99559517216464
회귀 계수값: [ -0.1 0.1 0. 3. -19.8 3.4 0. -1.7 0.4 -0. -0.9 0. -0.6]
- 회귀계수 : Nox(환경지수?) 값
회귀 계수(모델에 영향을 미치는 정도)가 큰 순서대로 정렬
# 회귀 계수를 큰 값 순으로 정렬하기 위해 Series로 생성. index가 컬럼명에 유의
coeff = pd.Series(data=np.round(lr.coef_, 1), index=X_data.columns )
coeff.sort_values(ascending=False)
RM 3.4
CHAS 3.0
RAD 0.4
ZN 0.1
INDUS 0.0
AGE 0.0
TAX -0.0
B 0.0
CRIM -0.1
LSTAT -0.6
PTRATIO -0.9
DIS -1.7
NOX -19.8
dtype: float64
Fold 셋으로 교차 검증을 수행하여 MSE, RMSE 구하기
from sklearn.model_selection import cross_val_score
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
lr = LinearRegression()
# cross_val_score( )로 5 Fold 셋으로 MSE 를 구한 뒤 이를 기반으로 다시 RMSE 구함.
neg_mse_scores = cross_val_score(lr, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
# cross_val_score(scoring="neg_mean_squared_error")로 반환된 값은 모두 음수
print(' 5 folds 의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 2))
print(' 5 folds 의 개별 RMSE scores : ', np.round(rmse_scores, 2))
print(' 5 folds 의 평균 RMSE : {0:.3f} '.format(avg_rmse))
5 folds 의 개별 Negative MSE scores: [-12.46 -26.05 -33.07 -80.76 -33.31]
5 folds 의 개별 RMSE scores : [3.53 5.1 5.75 8.99 5.77]
5 folds 의 평균 RMSE : 5.829
'빅데이터 분석가 양성과정 > Python - 머신러닝' 카테고리의 다른 글
| 회귀(Regression) - 규제 선형 회귀 (0) | 2024.07.12 |
|---|---|
| 회귀(Regression) - 다항 선형 회귀 (0) | 2024.07.12 |
| 회귀(Regression) - 선형 회귀 / 경사 하강법 (0) | 2024.07.12 |
| 실습) adult data 분류 (0) | 2024.07.11 |
| 머신러닝 분류 - 앙상블 러닝 (2) | 2024.07.11 |