
실습 - 캐글 : bike-sharing-demand
자전거 데이터 확인
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore", category=RuntimeWarning)
bike_df = pd.read_csv('./train.csv')
print(bike_df.shape)
bike_df.head(3)


bike_df.info()
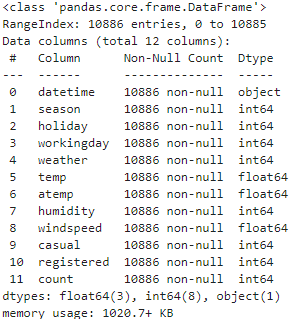
년,월,일,시 각각 분해
# 문자열을 datetime 타입으로 변경.
bike_df['datetime'] = bike_df.datetime.apply(pd.to_datetime)
# datetime 타입에서 년, 월, 일, 시간 추출
bike_df['year'] = bike_df.datetime.apply(lambda x : x.year)
bike_df['month'] = bike_df.datetime.apply(lambda x : x.month)
bike_df['day'] = bike_df.datetime.apply(lambda x : x.day)
bike_df['hour'] = bike_df.datetime.apply(lambda x: x.hour)
bike_df.head(3)

bike_df.info()
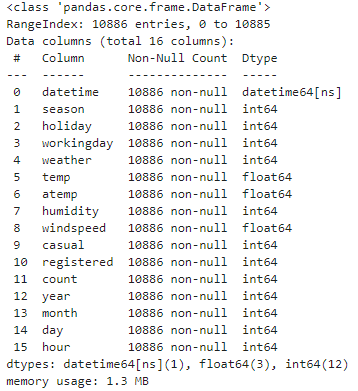
Data type 확인후 불필요한 목록 삭제
drop_columns = ['datetime','casual','registered']
bike_df.drop(drop_columns, axis=1,inplace=True)
에러 함수들 정의 후 선형회귀 학습/예측
from sklearn.metrics import mean_squared_error, mean_absolute_error
# log 값 변환 시 NaN등의 이슈로 log() 가 아닌 log1p() 를 이용하여 RMSLE 계산
def rmsle(y, pred):
log_y = np.log1p(y)
log_pred = np.log1p(pred)
squared_error = (log_y - log_pred) ** 2
rmsle = np.sqrt(np.mean(squared_error))
return rmsle
# 사이킷런의 mean_square_error() 를 이용하여 RMSE 계산
def rmse(y,pred):
return np.sqrt(mean_squared_error(y,pred))
# MSE, RMSE, RMSLE 를 모두 계산
def evaluate_regr(y,pred):
rmsle_val = rmsle(y,pred)
rmse_val = rmse(y,pred)
# MAE 는 scikit learn의 mean_absolute_error() 로 계산
mae_val = mean_absolute_error(y,pred)
print('RMSLE: {0:.3f}, RMSE: {1:.3F}, MAE: {2:.3F}'.format(rmsle_val, rmse_val, mae_val))
from sklearn.model_selection import train_test_split , GridSearchCV
from sklearn.linear_model import LinearRegression , Ridge , Lasso
y_target = bike_df['count']
X_features = bike_df.drop(['count'],axis=1,inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.3, random_state=0)
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
pred = lr_reg.predict(X_test)
evaluate_regr(y_test ,pred)
RMSLE: 1.165, RMSE: 140.900, MAE: 105.924
- RMSLE에 비해 RMSE값이 매우 크게 나왔다. 예측 에러가 매우 큰 값들이 섞여 있기 때문
예측값과 실제값 오차 확인
def get_top_error_data(y_test, pred, n_tops = 5):
# DataFrame에 컬럼들로 실제 대여횟수(count)와 예측 값을 서로 비교 할 수 있도록 생성.
result_df = pd.DataFrame(y_test.values, columns=['real_count'])
result_df['predicted_count']= np.round(pred)
result_df['diff'] = np.abs(result_df['real_count'] - result_df['predicted_count'])
# 예측값과 실제값이 가장 큰 데이터 순으로 출력.
print(result_df.sort_values('diff', ascending=False)[:n_tops])
get_top_error_data(y_test,pred,n_tops=5)
real_count predicted_count diff
1618 890 322.0 568.0
3151 798 241.0 557.0
966 884 327.0 557.0
412 745 194.0 551.0
2817 856 310.0 546.0
- 실제 값과 예측 값의 차이가 매우 큰 것을 확인할 수 있다
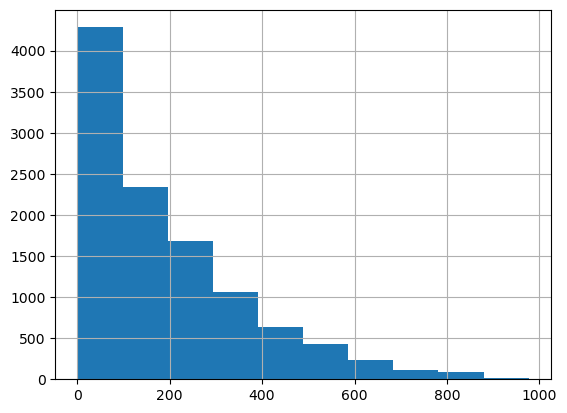
정규화 전 타겟값 분포
y_target.hist()
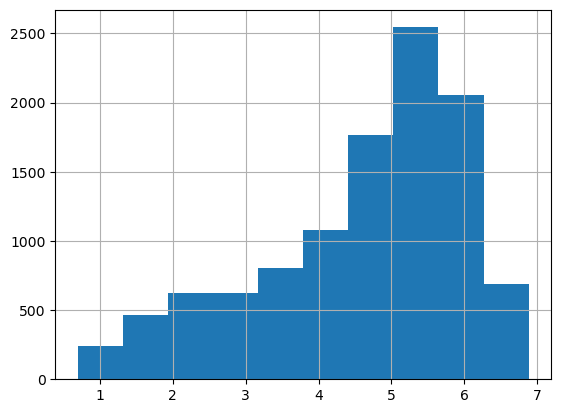
로그 변환 후 타겟값 분포 -> 어느 정도 정규분포를 이룬다
y_log_transform = np.log1p(y_target)
y_log_transform.hist()
# 타겟 컬럼인 count 값을 log1p 로 Log 변환
y_target_log = np.log1p(y_target)
# 로그 변환된 y_target_log를 반영하여 학습/테스트 데이터 셋 분할
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target_log, test_size=0.3, random_state=0)
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
pred = lr_reg.predict(X_test)
# 테스트 데이터 셋의 Target 값은 Log 변환되었으므로 다시 expm1를 이용하여 원래 scale로 변환
y_test_exp = np.expm1(y_test)
# 예측 값 역시 Log 변환된 타겟 기반으로 학습되어 예측되었으므로 다시 exmpl으로 scale변환
pred_exp = np.expm1(pred)
evaluate_regr(y_test_exp ,pred_exp)
RMSLE: 1.017, RMSE: 162.594, MAE: 109.286
- 아직도 RMSLE에 비해 RMSE값이 매우 크게 나왔다.
피처 별 회귀 계수 확인
coef = pd.Series(lr_reg.coef_, index=X_features.columns)
coef_sort = coef.sort_values(ascending=False)
sns.barplot(x=coef_sort.values, y=coef_sort.index)
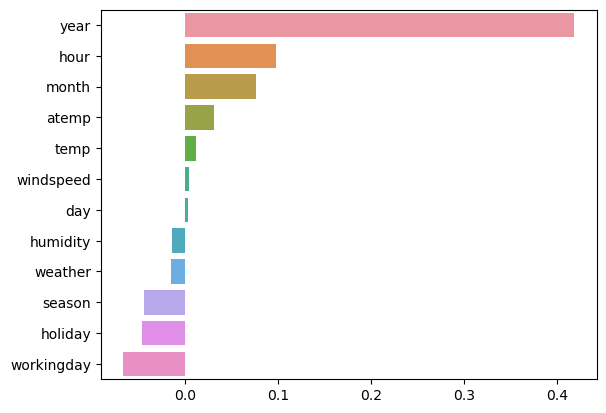
year(2011, 2012)가 영향력이 큰 것을 볼 수 있다. -> 해당 데이터는 2011년에 창업한 스타트업으로 2012년부터 더 성장해서 대여 수요량이 늘어난 것
원-핫 인코딩 후 다시 학습/예측
# 'year', month', 'day', hour'등의 피처들을 One Hot Encoding
X_features_ohe = pd.get_dummies(X_features, columns=['year', 'month','day', 'hour', 'holiday',
'workingday','season','weather'])
기본 선형회귀와 릿지, 라쏘 모델에 대해 성능 평가를 해주는 함수
# 원-핫 인코딩이 적용된 feature 데이터 세트 기반으로 학습/예측 데이터 분할.
X_train, X_test, y_train, y_test = train_test_split(X_features_ohe, y_target_log,
test_size=0.3, random_state=0)
# 모델과 학습/테스트 데이터 셋을 입력하면 성능 평가 수치를 반환
def get_model_predict(model, X_train, X_test, y_train, y_test, is_expm1=False):
model.fit(X_train, y_train)
pred = model.predict(X_test)
if is_expm1 :
y_test = np.expm1(y_test)
pred = np.expm1(pred)
print('###',model.__class__.__name__,'###')
evaluate_regr(y_test, pred)
# end of function get_model_predict
# model 별로 평가 수행
lr_reg = LinearRegression()
ridge_reg = Ridge(alpha=10)
lasso_reg = Lasso(alpha=0.01)
for model in [lr_reg, ridge_reg, lasso_reg]:
get_model_predict(model,X_train, X_test, y_train, y_test,is_expm1=True)
### LinearRegression ###
RMSLE: 0.590, RMSE: 97.688, MAE: 63.382
### Ridge ###
RMSLE: 0.590, RMSE: 98.529, MAE: 63.893
### Lasso ###
RMSLE: 0.635, RMSE: 113.219, MAE: 72.803
이전보다 RMSE가 많이 줄은 것을 볼 수 있다
coef = pd.Series(lr_reg.coef_ , index=X_features_ohe.columns)
coef_sort = coef.sort_values(ascending=False)[:10]
sns.barplot(x=coef_sort.values , y=coef_sort.index)
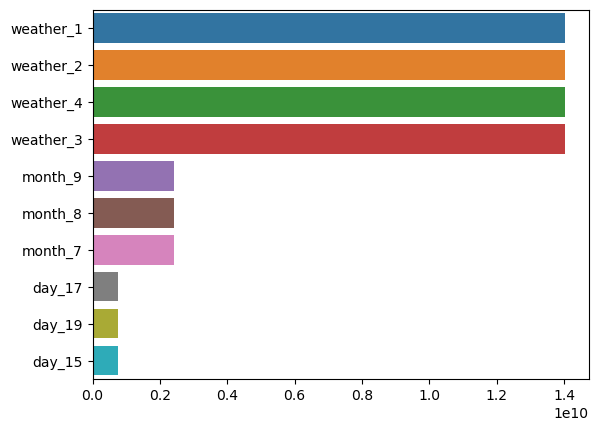
회귀 트리 사용
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
# 랜덤 포레스트, GBM, XGBoost, LightGBM model 별로 평가 수행
rf_reg = RandomForestRegressor(n_estimators=500)
gbm_reg = GradientBoostingRegressor(n_estimators=500)
for model in [rf_reg, gbm_reg]:
# XGBoost의 경우 DataFrame이 입력 될 경우 버전에 따라 오류 발생 가능. ndarray로 변환.
get_model_predict(model,X_train.values, X_test.values, y_train.values, y_test.values,is_expm1=True)
RandomForestRegressor
RMSLE: 0.354, RMSE: 49.946, MAE: 30.974
GradientBoostingRegressor
RMSLE: 0.330, RMSE: 53.345, MAE: 32.750
'빅데이터 분석가 양성과정 > Python - 머신러닝' 카테고리의 다른 글
| 군집화 (K-Means) (0) | 2024.07.12 |
|---|---|
| 차원축소(Unsupervised Learning) (4) | 2024.07.12 |
| 회귀(Regression) - 로지스틱 회귀 / 회귀 트리 (0) | 2024.07.12 |
| 회귀(Regression) - 데이터 전처리(정규화, 로그 변환, 스케일러, 원-핫 인코딩) (0) | 2024.07.12 |
| 회귀(Regression) - 규제 선형 회귀 (0) | 2024.07.12 |
실습 - 캐글 : bike-sharing-demand
자전거 데이터 확인
import numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as plt%matplotlib inlineimport warningswarnings.filterwarnings("ignore", category=RuntimeWarning)bike_df = pd.read_csv('./train.csv')print(bike_df.shape)bike_df.head(3)
bike_df.info()년,월,일,시 각각 분해
# 문자열을 datetime 타입으로 변경. bike_df['datetime'] = bike_df.datetime.apply(pd.to_datetime)# datetime 타입에서 년, 월, 일, 시간 추출bike_df['year'] = bike_df.datetime.apply(lambda x : x.year)bike_df['month'] = bike_df.datetime.apply(lambda x : x.month)bike_df['day'] = bike_df.datetime.apply(lambda x : x.day)bike_df['hour'] = bike_df.datetime.apply(lambda x: x.hour)bike_df.head(3)
bike_df.info()
Data type 확인후 불필요한 목록 삭제
drop_columns = ['datetime','casual','registered']bike_df.drop(drop_columns, axis=1,inplace=True)에러 함수들 정의 후 선형회귀 학습/예측
from sklearn.metrics import mean_squared_error, mean_absolute_error# log 값 변환 시 NaN등의 이슈로 log() 가 아닌 log1p() 를 이용하여 RMSLE 계산def rmsle(y, pred): log_y = np.log1p(y) log_pred = np.log1p(pred) squared_error = (log_y - log_pred) ** 2 rmsle = np.sqrt(np.mean(squared_error)) return rmsle# 사이킷런의 mean_square_error() 를 이용하여 RMSE 계산def rmse(y,pred): return np.sqrt(mean_squared_error(y,pred))# MSE, RMSE, RMSLE 를 모두 계산 def evaluate_regr(y,pred): rmsle_val = rmsle(y,pred) rmse_val = rmse(y,pred) # MAE 는 scikit learn의 mean_absolute_error() 로 계산 mae_val = mean_absolute_error(y,pred) print('RMSLE: {0:.3f}, RMSE: {1:.3F}, MAE: {2:.3F}'.format(rmsle_val, rmse_val, mae_val))
from sklearn.model_selection import train_test_split , GridSearchCVfrom sklearn.linear_model import LinearRegression , Ridge , Lassoy_target = bike_df['count']X_features = bike_df.drop(['count'],axis=1,inplace=False)X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.3, random_state=0)lr_reg = LinearRegression()lr_reg.fit(X_train, y_train)pred = lr_reg.predict(X_test)evaluate_regr(y_test ,pred)RMSLE: 1.165, RMSE: 140.900, MAE: 105.924
- RMSLE에 비해 RMSE값이 매우 크게 나왔다. 예측 에러가 매우 큰 값들이 섞여 있기 때문
예측값과 실제값 오차 확인
def get_top_error_data(y_test, pred, n_tops = 5): # DataFrame에 컬럼들로 실제 대여횟수(count)와 예측 값을 서로 비교 할 수 있도록 생성. result_df = pd.DataFrame(y_test.values, columns=['real_count']) result_df['predicted_count']= np.round(pred) result_df['diff'] = np.abs(result_df['real_count'] - result_df['predicted_count']) # 예측값과 실제값이 가장 큰 데이터 순으로 출력. print(result_df.sort_values('diff', ascending=False)[:n_tops]) get_top_error_data(y_test,pred,n_tops=5)real_count predicted_count diff
1618 890 322.0 568.0
3151 798 241.0 557.0
966 884 327.0 557.0
412 745 194.0 551.0
2817 856 310.0 546.0
- 실제 값과 예측 값의 차이가 매우 큰 것을 확인할 수 있다
정규화 전 타겟값 분포
y_target.hist()로그 변환 후 타겟값 분포 -> 어느 정도 정규분포를 이룬다
y_log_transform = np.log1p(y_target)y_log_transform.hist()
# 타겟 컬럼인 count 값을 log1p 로 Log 변환y_target_log = np.log1p(y_target)# 로그 변환된 y_target_log를 반영하여 학습/테스트 데이터 셋 분할X_train, X_test, y_train, y_test = train_test_split(X_features, y_target_log, test_size=0.3, random_state=0)lr_reg = LinearRegression()lr_reg.fit(X_train, y_train)pred = lr_reg.predict(X_test)# 테스트 데이터 셋의 Target 값은 Log 변환되었으므로 다시 expm1를 이용하여 원래 scale로 변환y_test_exp = np.expm1(y_test)# 예측 값 역시 Log 변환된 타겟 기반으로 학습되어 예측되었으므로 다시 exmpl으로 scale변환pred_exp = np.expm1(pred)evaluate_regr(y_test_exp ,pred_exp)RMSLE: 1.017, RMSE: 162.594, MAE: 109.286
- 아직도 RMSLE에 비해 RMSE값이 매우 크게 나왔다.
피처 별 회귀 계수 확인
coef = pd.Series(lr_reg.coef_, index=X_features.columns)coef_sort = coef.sort_values(ascending=False)sns.barplot(x=coef_sort.values, y=coef_sort.index)
year(2011, 2012)가 영향력이 큰 것을 볼 수 있다. -> 해당 데이터는 2011년에 창업한 스타트업으로 2012년부터 더 성장해서 대여 수요량이 늘어난 것
원-핫 인코딩 후 다시 학습/예측
# 'year', month', 'day', hour'등의 피처들을 One Hot EncodingX_features_ohe = pd.get_dummies(X_features, columns=['year', 'month','day', 'hour', 'holiday', 'workingday','season','weather'])기본 선형회귀와 릿지, 라쏘 모델에 대해 성능 평가를 해주는 함수
# 원-핫 인코딩이 적용된 feature 데이터 세트 기반으로 학습/예측 데이터 분할. X_train, X_test, y_train, y_test = train_test_split(X_features_ohe, y_target_log, test_size=0.3, random_state=0)# 모델과 학습/테스트 데이터 셋을 입력하면 성능 평가 수치를 반환def get_model_predict(model, X_train, X_test, y_train, y_test, is_expm1=False): model.fit(X_train, y_train) pred = model.predict(X_test) if is_expm1 : y_test = np.expm1(y_test) pred = np.expm1(pred) print('###',model.__class__.__name__,'###') evaluate_regr(y_test, pred)# end of function get_model_predict # model 별로 평가 수행lr_reg = LinearRegression()ridge_reg = Ridge(alpha=10)lasso_reg = Lasso(alpha=0.01)for model in [lr_reg, ridge_reg, lasso_reg]: get_model_predict(model,X_train, X_test, y_train, y_test,is_expm1=True)### LinearRegression ###
RMSLE: 0.590, RMSE: 97.688, MAE: 63.382
### Ridge ###
RMSLE: 0.590, RMSE: 98.529, MAE: 63.893
### Lasso ###
RMSLE: 0.635, RMSE: 113.219, MAE: 72.803
이전보다 RMSE가 많이 줄은 것을 볼 수 있다
coef = pd.Series(lr_reg.coef_ , index=X_features_ohe.columns)coef_sort = coef.sort_values(ascending=False)[:10]sns.barplot(x=coef_sort.values , y=coef_sort.index)회귀 트리 사용
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor# 랜덤 포레스트, GBM, XGBoost, LightGBM model 별로 평가 수행rf_reg = RandomForestRegressor(n_estimators=500)gbm_reg = GradientBoostingRegressor(n_estimators=500)for model in [rf_reg, gbm_reg]: # XGBoost의 경우 DataFrame이 입력 될 경우 버전에 따라 오류 발생 가능. ndarray로 변환. get_model_predict(model,X_train.values, X_test.values, y_train.values, y_test.values,is_expm1=True)RandomForestRegressor
RMSLE: 0.354, RMSE: 49.946, MAE: 30.974
GradientBoostingRegressor
RMSLE: 0.330, RMSE: 53.345, MAE: 32.750
'빅데이터 분석가 양성과정 > Python - 머신러닝' 카테고리의 다른 글
| 군집화 (K-Means) (0) | 2024.07.12 |
|---|---|
| 차원축소(Unsupervised Learning) (4) | 2024.07.12 |
| 회귀(Regression) - 로지스틱 회귀 / 회귀 트리 (0) | 2024.07.12 |
| 회귀(Regression) - 데이터 전처리(정규화, 로그 변환, 스케일러, 원-핫 인코딩) (0) | 2024.07.12 |
| 회귀(Regression) - 규제 선형 회귀 (0) | 2024.07.12 |