

추천시스템 목적
- 유튜브, 아마존, 넷플릭스 등 수많은 서비스들에서 개인화된 추천시스템을 개발하고 운영합니다.
- 각 고객의 니즈와 선호에 맞는 컨텐츠나 상품이 추천되었을 때 비즈니스 효과(전환율, 재방문율 등)가 통계적으로 더 높음이 이미 증명되었기 때문입니다.
- 개인화 추천시스템의 비즈니스 효과가 비개인화 대비해서 더 좋은 이유는 무엇일까요?
- 고객이 직접 검색을 통해 원하는 항목을 찾는데 들어가는 시간과 노력을 줄여주기 때문이며 (목적성 구매, 소비의 경우)
- 고객으로 하여금 특별한 위치와 관계임을 은연중에 전달하기 때문 (기업이 고객과 관계를 중시하는 느낌 전달)
- 기업은 고객의 데이터를 분석/모델링하여 비즈니스 성과를 극대화하기 위해 아래 요인을 균형있게 고려한 추천시스템을 개발하고자 노력합니다.
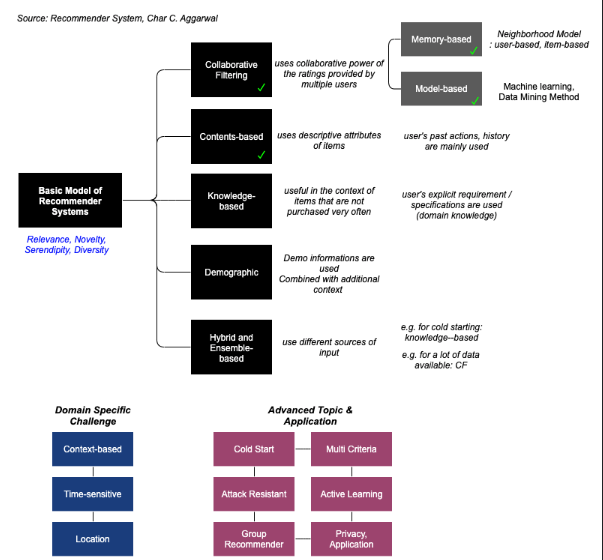
- 고객의 선호와 니즈에 관련성이 높고 (Relevance)
- 고객이 기존에 느끼지 못한 새로움을 전달하며 (Novelty)
- 관련이 없더라도 새로운 호기심을 자극하며 (Serendipity)
- 최대한 다양한 컨텐츠, 상품을 경험할수 있도록 전달 (Diversity)
추천 성능 지표
오프라인 지표
- 평점(실수) 예측 기반 평가 지표
- RMSE (Root Mean Square Error)
- MAE (Mean Absoulte Error)
- 랭킹 예측 기반 평가 지표
- Precision@K와 Recall@K
- MAP@K (Mean Average Precision@K)
- NDCG@K (Normalized Discounted Cumulative Gain)
- Hit Ratio@K
- 주로 배포 전 의사결정(어떤 모델을 배포할지)을 하기 위해 활용하고 실제 사용자 피드백을 사전 예측하기 위해 이용
온라인 지표 (via AB Test)
- 실제 서비스에 배포한후 CTR(Click Through Rate), PV(Page View), 매출 등 비즈니스 지표에 미친 영향도 측정
- AB Test를 통해 지속적으로 추천 알고리즘을 개선
- 주로 사용자 피드백을 참고해 다음 Iteration에서 기획 및 개발에 필요한 의사결정을 진행하고 프로젝트 성과를 측정/공유하는데 이용
MLOPS 지표
- 추천 성능에 영향을 줄수 있는 선행 요인들을 지표화하여 트래킹
- 피처 퀄리티, 데이터양(사이즈), cpu/ram/gpu 리소스 및 파이프라인 현황 등
- 이상치 탐지 등 알고리즘이 적용된 경우가 많으며, 알람 시스템을 통해 사전에 장애 및 이슈를 대응하기 위해 이용


협업 필터 시스템 ( 메모리 기반 ) - https://kmhana.tistory.com/31
추천 시스템 기본 - 협업 필터링(Collaborative Filtering) - ②
*크롬으로 보시는 걸 추천드립니다* 대표적 추천 시스템인 협업 필터링(Collaborative Filtering) 중 Memory-Based Approach에 대해서 다루어보았습니다 https://kmhana.tistory.com/31?category=882777 Have A Nice AI kmhana.tist
kmhana.tistory.com
협업 필터 시스템 ( 모델 기반 ) - https://kmhana.tistory.com/32
추천 시스템 기본 - 협업 필터링(Collaborative Filtering) - ①
*크롬으로 보시는 걸 추천드립니다* 우리 일상생활에 녹아있는 "인공지능(AI)"에는 추천 시스템이 있다는 것을 소개해 드렸습니다 https://kmhana.tistory.com/30 Have A Nice AI kmhana.tistory.com 이제 부터는 조
kmhana.tistory.com
[출처] 메타코드M
'코드 및 쿼리문 > 강의 - 메타코드M' 카테고리의 다른 글
| Kaggle 데이터를 활용한 개인화 추천시스템(5) (1) | 2024.12.10 |
|---|---|
| Kaggle 데이터를 활용한 개인화 추천시스템(4) (1) | 2024.12.05 |
| Kaggle 데이터를 활용한 개인화 추천시스템(3) (2) | 2024.12.05 |
| Kaggle 데이터를 활용한 개인화 추천시스템(1) (1) | 2024.12.02 |
| 5년차 대기업 DA가 알려주는 A/B테스트 실무 방법론 (0) | 2024.12.02 |